In this blog post we're going to cover a concepts and implementation behind collaborative 2-dimensional tables, with set of operation that could make them useful to work as spread sheets - popular in products like MS Excel or Google Sheets. There are many open source and commercial alternatives on the market, but at the moment of writing this post a few of them offer any sort of collaborative features, even fewer are capable to extend that to offline-first capabilities.
CRDT table architecture
Below we'll be describing the technical overview of the data structure, which source code can be find in this Github repository.
Before going to implementation details, let's specify the characteristics of the spread sheets workloads. Once data volume grows, its impossible to optimize the data structure for all work patterns. We need to pick our battles. For this reason we need to construct some initial assumptions:
- Some spread sheets can consists of hundreds of columns and (in some cases) hundreds of thousands of rows. For this reason, the size of metadata per row (and per cell) matters.
- Relative position of rows is usually not that important - unless we apply specific ordering rules (like order rows by column X), the insertion order rarely changes the meaning of the entire context. This is very much in contrast to ie. text editors where preserving the intended order of inserted characters is a grave matter. For that reason we acknowledge interleaving as an acceptable tradeoff.
- The majority of changes come from cell updates, including deletion of cell contents. Our conflict resolution should work on cell level not row level (enabling users to concurrently edit different cells of the same row without conflicts).
- The majority of inserts are actually appends of consecutive ranges of rows and columns, including copy/pasting massive amount of rows from another source. Inserting rows in between existing rows can happen but it's less common than ie. in case of text editors.
- Even if our sheet has thousands of rows, we usually render only a handful of them (adjacent to each other within window boundaries) at the time. For this reason its good to keep similarity between how rows are presented to a user, and their actual in-memory layout (read: if we need to present user rows [1..N], we don't want to do so by doing N * random memory access for each row).
With these in mind let's start from visual representation of our data structure:
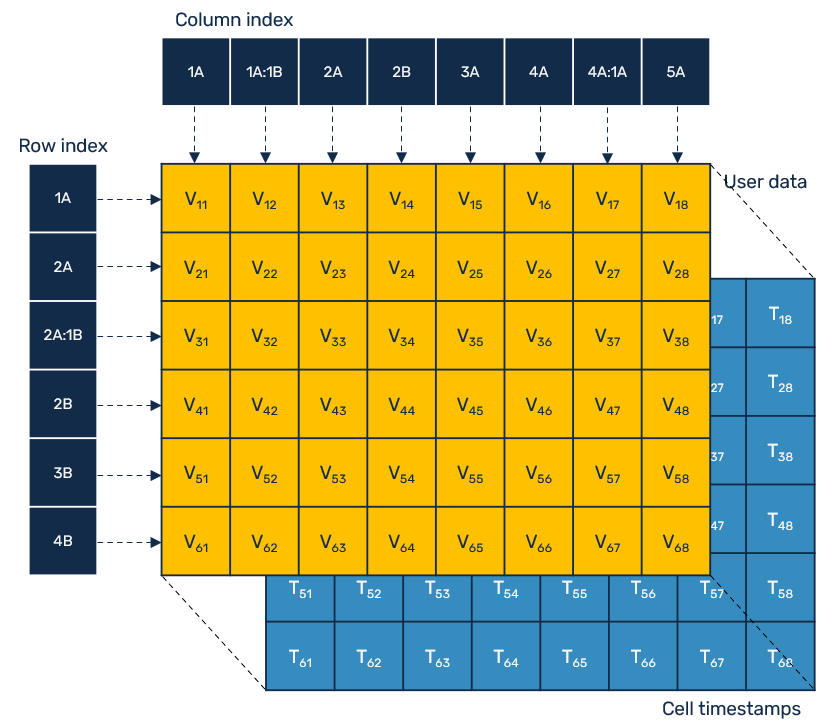
First, we put all inputs into a single userData table - here it's represented as an array of rows, and each row: as an array of cells. While this table doesn't contain any CRDT-specific metadata - so that we could use it straight away ie. as a data source for some UI component - it has a companion versions table, which contains timestamps for each cell under the same row/column index. This means, that each cell effectively works as a last-write-wins register. It's enough for our purposes, but potentially it could be changed ie. keep cell data timestamp together for better memory locality or even allow other CRDT types like text structures or maps to enable conflict-free editing of different cell properties.
Another issue to solve is need for tracking positions of rows and columns. If we would refer to cells by their row/column numeric indexes, it would be soon messed up once another user decided to prepend some rows/columns while we were updating them.
While most of the indexed sequences nowadays operate on interleave-resistant algorithms, they do so because they operate in context, where interleaving can produce invalid and hard to fix state - mainly text editors. On the flip side, they pretty much always need to rely on tombstones, since these algorithms require neighbors location in order to perform conflict resolution. However given our assumptions from points 1 and 2, we can extend our toolkit to other options.
Here, we're going to keep track of inserted columns and rows by using LSeq data structure: represented in our case as array of fractional keys. While we did describe LSeq in the past, let's gloss over it very quickly: linear sequence inserts elements at index i by generating key for new inserted entry, that's lexically smaller than the key at position i+1 and greater than the key at position i-1.
What's important here is that, neighbour keys are needed only during key generation time, not a conflict resolution time. It means that if we can guarantee causality of our operations (and prevent duplicate updated), we don't need to preserve tombstones of removed elements. Therefore:
- removing rows or columns doesn't require any extra memory
- we don't need to keep around information about neighbours for every row/column - key alone is enough, which for many cases means 3x less space.
- our linear sequence keys order always matches row/column order, meaning key lookups have logarithmic complexity while our range scans are sequential
- since keys are expected to be placed in lexical order, they can be nicely mapped to existing data structures having the same properties ie. B+Trees used by persistent storage engines.
That being said, our implementation uses tombstones simply because we don't use replication protocol that preserves causality - we simply shove updates around. With a protocol capable of deduplicating updates we wouldn't need them.
Fractional index
Let's quickly gloss over the implementation of LSeq data structure we'll use here. Our index is basically a sorted list of fractional keys:
/** The lowest possible Fractional Key. No generated key can be lower than it. */
const MIN_KEY = [0]
/** The highest possible Fractional Key. No generated key can be higher than it. */
const MAX_KEY = [Number.MAX_SAFE_INTEGER]
class FractionalIndex {
constructor() {
this.entries = []
this.tombstones = []
}
getIndexByKey(key) {
const e = binarySearch(this.entries, key, 0, this.entries.length - 1)
if (!e.found) {
const { index, found } = binarySearch(this.tombstones, key, 0, this.tombstones.length - 1)
if (found) {
return { index: e.index, tombstoned: this.tombstones[index].value }
}
}
return e
}
neighbors(index) {
// if index happens at list boundaries, substitute missing left right with MIN_KEY or MAX_KEY
let left = (index > 0 && index <= this.entries.length ? this.entries[index-1].key : MIN_KEY)
const right = (index < this.entries.length ? this.entries[index].key : MAX_KEY)
return { left, right }
}
// ... rest of the implementation
}
const binarySearch = (map, key, start, end) => {
while (start <= end) {
let m = (start + end) >> 1
let cmp = compareKeys(map[m].key, key)
if (cmp === 0) {
return { index: m, found: true }
} else if (cmp < 0) {
start = m + 1
} else {
end = m - 1
}
}
// searched key is not in a map, return index
// where it should be inserted
return { index: end + 1, found: false }
}
We use a binary search to find an index of an inserted key - or an index where the key should be inserted in case if it didn't exist in index yet. Those indexes map directly to placement of rows and columns within Table's userData and versions.
Inserts and updates
We cover inserts and updates together, as they are practically realized the same way, once we map them onto update payload.
class Table {
insertRows(index, values) {
const rows = []
// check if we don't need to add new columns to accomodate
// incoming row cells
const columns = this.adjustColumns(0, values)
// get neighbours at index
let { left, right } = this.rowIndex.neighbors(index)
for (let value of values) {
const rowKey = generateKey(this.hashId, left, right)
const entry = new Entry(rowKey, value)
rows.push(entry)
// newly created row entry becomes new left neighbor
left = rowKey
}
const timestamp = this.incVersion()
const update = { timestamp, upsertRows: { columns, rows } }
this.apply(update)
this.onUpdate(update)
}
}
We only present inserting new rows, as inserting columns is analogous but simplified version of this method.
Additionally we'll provide a method to update cells in a given window - they can be scattered over multiple rows, but the order of columns in each update cell must match. Unlike methods above this one doesn't arbitrarily insert new rows or columns, but focuses on updating existing ones. This could be useful ie. when you want to copy/paste window of data onto existing table.
class Table {
updateCells(row, col, values) {
// check if we don't need to add new columns to accomodate
// incoming row cells
const columns = this.adjustColumns(col, values)
const rows = []
let i = row
let lastRow = this.rowIndex.lastKey
for (let value of values) {
let entry
if (i < this.rowIndex.length) {
// update existing row, starting from given column
entry = new Entry(this.rowIndex.entries[i].key, value)
} else {
// we went over existing rows
// append new rows at the end of the table
let rowKey = generateKey(this.hashId, lastRow, MAX_KEY)
entry = new Entry(rowKey, value)
lastRow = rowKey
}
rows.push(entry)
i++
}
const update = {
timestamp: this.incVersion(),
upsertRows: { columns, rows }
}
this.apply(update)
this.onUpdate(update)
}
}
Additionaly this method is capable of expanding a table by new rows or columns if updated rectangle spans beyound existing boundaries - we must have such option as you never know how the table dimensions on remote peer change while we were making an update.
There are few things to notice about our update object format:
- Update is described with a single timestamp and all affected cells will share it. This wouldn't work if we wanted to replicate and merge entire table state, but it works for individual updates and copy/pasting windows of data as well.
- Within update we always refer to columns and rows positions in table using fractional keys: that's because updates can happen concurrently, so we cannot rely on natural indexes (they could change when other update happened).
- While update comes with a matrix of rows, it always must include list of fractional keys for affected columns, this list always equal to the longest row in an update. This way we can also send updates modifying not only entire rows, but also their fragments (even individual cells).
Now we created an update, but it didn't do any changes over our table. This is a responsibility of apply methods - for simplicity we use them as common mechanism to apply both locally and remotely generated updates.
class Table {
applyUpsertRows(columns, entries, version) {
// there may be new columns in this update, add them first
const columnIndexes = this.applyUpsertColumns(columns, version)
for (let entry of entries) {
let f = this.rowIndex.getIndexByKey(entry.key)
if (f.tombstoned && isHigher(f.tombstoned, version)) {
// this entry was already deleted with a higher timestamp
continue
}
let row
let cellsVersions
if (f.found) {
// applyUpsertColumns already adjusted the columns
row = this.userData[f.index]
cellsVersions = this.versions[f.index]
} else {
let index = f.index
// create a new 0-initialized rows
this.rowIndex.insert(index, entry.key, null)
row = new Array(this.colIndex.length).fill(null)
versions = new Array(this.colIndex.length).fill(null)
this.userData.splice(index, 0, row)
this.versions.splice(index, 0, cellsVersions)
}
// merge incoming entry into the `row` in current table
for (let i=0; i < entry.value.length; i++) {
let newValue = entry.value[i]
let cellIndex = columnIndexes[i]
if (cellIndex >= 0) {
// cellIndex < 0 means that column was already removed
// with higher version timestamp
let cellVersion = cellsVersions[cellIndex]
if (isHigher(version, cellVersion)) {
versions[cellIndex] = version
row[cellIndex] = newValue
}
}
}
}
}
}
Deletions
Compared to upserts, deletions are fairly easy. All we need to provide is an array of fractional keys to be deleted and a deletion timestamp.
class Table {
deleteRows(index, length = 1) {
const rows = []
const end = Math.min(this.rowIndex.length, index + length)
for (let i = index; i < end; i++) {
const row = this.rowIndex.entries[i].key
rows.push(row)
}
const timestamp = this.incVersion()
const update = { timestamp, deleteRows: { rows } }
this.apply(update)
this.onUpdate(update)
}
// deleteColumns works in the same manner on colIndex
}
The issue we need to remember about is that our table generally preserves add-wins/last-write-wins semantics, meaning that we cannot just blindly delete row or column of data: potentially some of their cells might have been updated with a higher timestamp. Therefore we first nullify cells with a lower version and in case if this successfully affected all known rows or columns, we're free to remove them. This also means that we need to remove a corresponding entry in fractional index for rows/columns.
class Table {
applyDeleteRows(rows, version) {
for (let key of rows) {
let f = this.rowIndex.getIndexByKey(key)
if (f.found) {
let rowIndex = f.index
// check if there are entries with higher version than
// current delete timestamp
let row = this.userData[rowIndex]
let versions = this.versions[rowIndex]
let keep = false
for (let i=0; i < row.length; i++) {
if (isHigher(version, versions[i])) {
// deletion timestamp is higher than latest update
row[i] = null
versions[i] = version
} else if (row[i] !== null) {
// confirm that this cell was not already deleted
// we cannot remove row, cell has newer data
keep = true
}
}
if (!keep) {
// add deleted row to tombstones
this.userData.splice(rowIndex, 1)
this.versions.splice(rowIndex, 1)
// remove row from fractional map
this.rowIndex.remove(rowIndex)
this.rowIndex.tombstone(key, version)
}
} else {
this.rowIndex.tombstone(key, version)
}
}
}
}
Now, this behaviour may be questionable: some may argue that if there were cell updates that happened after deleted row/column, we should undo entire deletion proces instead of partially clearing some of the cells. It can be done, but this is simply what we did here, as it spares us row/column level timestamp tracking and tombstones, meaning simpler implementation and less metadata around.
Selections
Selections are another very useful concept. When working with spread sheets, quite often we want to be able to select a window of data. Common examples:
- Creating ranges of arguments for formulas like
=SUM(A1:B3). - Applying formatting attributes to multiple cells.
- Merging cells together.
- Rendering a piece of table ie. we don't want user view to start flickering because someone started copy/pasting rows or columns prior to displayed content position. We want to be able to anchor the rendered view position.
Using markers like A1:B3 mentioned above has common problem: they represent current order as observed by user. When other users will start to concurrently insert/remove rows or cells, these positions may no longer refer to fragments of data we intended them to. For this reason, we're going to represent our selections as a combination of two opposite points using logical indexing (our fractional keys) instead:
select(x, y) {
const { upperLeft, lowerRight } = normalizeArea(x, y)
if (upperLeft.row < 0 || upperLeft.col < 0 || lowerRight.row >= this.rowIndex.length || lowerRight.col >= this.colIndex.length) {
throw new Error('selected area is outside of the bound of the table')
}
const corner1 = {
row: generateKey(0xffffffff,
upperLeft.row === 0 ? MIN_KEY : this.rowIndex.entries[upperLeft.row - 1].key,
upperLeft.row === this.rowIndex.length ? MAX_KEY : this.rowIndex.entries[upperLeft.row].key),
col: generateKey(0xffffffff,
upperLeft.col === 0 ? MIN_KEY : this.colIndex.entries[upperLeft.col - 1].key,
upperLeft.col === this.colIndex.length ? MAX_KEY : this.colIndex.entries[upperLeft.col].key),
}
const corner2 = {
row: generateKey(0,
lowerRight.row === this.rowIndex.length ? MIN_KEY : this.rowIndex.entries[lowerRight.row].key,
lowerRight.row + 1 >= this.rowIndex.length ? MAX_KEY : this.rowIndex.entries[lowerRight.row + 1].key),
col: generateKey(0,
lowerRight.col === this.colIndex.length ? MIN_KEY : this.colIndex.entries[lowerRight.col].key,
lowerRight.col + 1 >= this.colIndex.length ? MAX_KEY : this.colIndex.entries[lowerRight.col + 1].key),
}
return new Selection(corner1, corner2)
}
If we want to get a view on actual data using selection, all we need is to map fractional keys back to the indexes they supposedly should be inserted in within a table we're interested in:
class Table {
view(selection) {
const {upperLeft, lowerRight} = materializeSelection(this, selection)
const view = []
for (let i = upperLeft.row; i < lowerRight.row; i++) {
let row = this.userData[i]
let res = []
for (let j = upperLeft.col; j < lowerRight.col; j++) {
res.push(row[j])
}
view.push(res)
}
return view
}
}
const materializePosition = (table, pos) => {
const row = table.rowIndex.getIndexByKey(pos.row)
const col = table.colIndex.getIndexByKey(pos.col)
return { row: row.index, col: col.index }
}
const materializeSelection = (table, selection) => {
const x = materializePosition(table, selection.corner1)
const y = materializePosition(table, selection.corner2)
return normalizeArea(x, y)
}
Keep in mind that when we're referring to ranges, we actually what to refer to spaces between elements at given indexes - hence notion of left/right side inclusive/exclusive ranges. Same problem concerns windows of data. This usually requires keeping additional flags around. Moreover, if we want to mark an entire range of values (eg. all current and future elements of a row/column), we need additional way to describe it as well.
What's interesting here, is that we again use LSeq fractional keys to our advantage. As you can see in snippets above, when defining corners of our selection, we're not using fractional keys of the corresponding rows. Instead we generate a new ones, existing at the boundaries precisely describing our selection. We can describe inclusivity/exclusivity of ranges by thinkering with generated keys to ensure that no user-defined row will ever be positioned before/after them.
Optimizations
Now, let's finish with some ideas on how to improve our implementation. These are not included in github repository atm, but may serve as a food for thought for the future.
Indexing selections
One of the popular scenarios for selections is to use them as parameters in formulas - so that we can preserve data window as new rows and columns are added - where we want to compute cell's value. However for such thing to become useful, we'd need to add some degree of reactivity: whenever a value inside of selection changes, we need to recompute formulas in all affected cells. For that we may need to quickly locate selections containing given cell or those that intersect with updated range ie. when we copy paste area of cell values at once.
With small number of listening selections, doing a brute force check over all of them may be probably enough. However let's propose an interesting solution in search of a problem :)
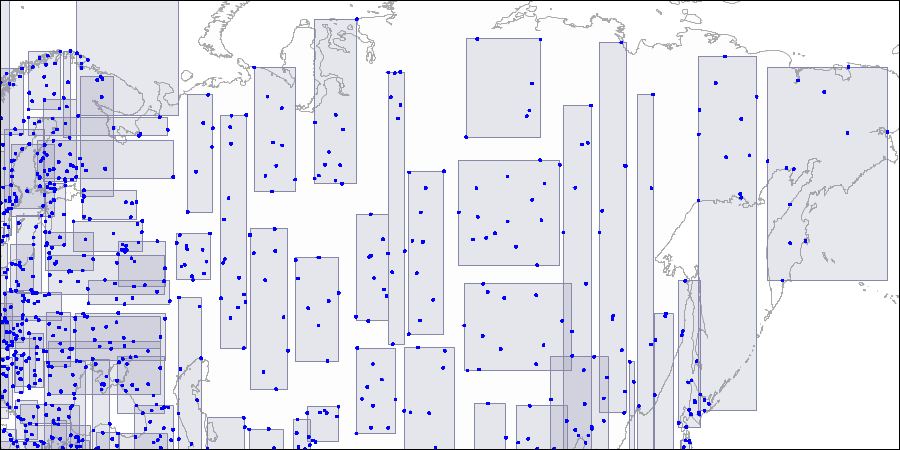
Indexing selections for fast constains/overlaps search operations may sound like a hard problem. However in the past we already covered concept of index structures optimized for multi-dimensional values: R-Trees. Below you can see how databases like Postgres use R-Tree to recursively split search space to improve lookups of geographical data.
The same foundation can be used in our case. Let's quickly reintroduce the basics in context of selections:
R-Tree is build on B+Tree, where we have a fixed-size nodes of keys/areas (here: selections). Keys in each node can be summarized as another selection that fits them all within its boundaries. This way keys can be grouped and build a recursive hierarchical tree structure. When node is full and a new selection needs to be inserted, we split that node in two and assign existing values as follows - pick two selections that are most far away from each other as seeds for newly created buckets, then split remaining values from old bucket by computing how much area covered of each bucket would grow if that key would have to be added there and pick the one where this growth rate is lower.
This definition requires two new measurements to operate for selection:
- Distance between selections: which could be computed as number of rows/columns between corners of both selections.
- Area coverage of a selection: which could be counted as a number of cells included in it.
Since these calculations are not cheap, it might turn out that such R-tree index wouldn't outperform brute-force scan until we take a greater number (hundreds, thousands?) of selections into account.
Moving rows/columns
We already discussed concept of conflict free reordering in scope of YATA indexed sequences algorithm in the past. Fortunately that algorithm was pretty universal. It's also portable to LSeq we use here.
In the past we mentioned that in context of concurrent updates, delete+add element is not an equivalent to moving it. In case if another concurrent move was about to happen, such item would be deleted twice then reappear twice in two different places. Also any updates performed on old version of element could potentially disappear. This is because if we count it as two individual delete+insert operations our moved element is no longer distinguishable from newly inserted one.
Now, if we're talking about LSeq, we can technically implement move(source, destination) as simple delete+upsert (with a little twist):
- Create new fractional key at a destination position.
- Copy moved row's contents together with their version timestamps, and insert them under new key we created at pt.1.
- Delete row from old position.
- Extra step: within Fractional index, create a dictionary (let's call it testament) where the key is source position, and value contains a destination position and timestamp when
moveoccurred (eg.{inheritor:FractionalKey,timestamp:Version}).
Thanks to pt.4 we're able to maintain the link between deleted and reinserted rows. Practice is ofc. a little more complicated as we need to take testament into account during other concurrent operations:
- All methods that return row/column by key - used when applying updates - need an additional check if that key exists in testament. If so, it has been moved (possibly recursively). Therefore we may need to follow through and return the last descendant.
- Concurrent move can be resolved by comparing testament entry with incoming move. Since we have version timestamps for both of them, we can pick either last-write-wins or first-write-wins strategy. Either way we merge loosing row into winning one and delete the looser. Additionally deleted one marks a winner as its inheritor in the testament map so that other concurrent updates that may refer to loosing entry will know where they should be redirected.
Such approach allows us to perform moves while still maintaining 1-1 mapping between our table row order and an read view presented to user. The major performance drawback is an additional testament lookup every time we want to update the row.
Column-oriented serialization
The table we described here is row-oriented (array of rows). However when it comes to serialization, it turns out that serializing data by columns is often more feasible. It's because cells existing in the same columns are more likely to have the same data type, and having the same type can make a huge difference. Examples:
- Column of boolean values (usually at least 1 byte per cell) can be stored as a bitmap (1bit per cell, 8 times less), and further compressed if necessary.
- Enums (finite set of repeating strings) can be cached and refered to using numbers encoded as variable integers (1-8 bytes depending on the number of enum cases).
- For timestamps (usually at least 8B) we can get the lowest timestamp in a column, and then store remaining ones as deltas. Moreover if our column stores them as ie. timeseries data, next timestamp can be a delta of its predecessor (a.k.a. delta of deltas encoding) - it means that quite often we can store such values using 1-5B with variable encoding.
Reducing timestamp footprint
What's worth noticing here is that in our case each cell has it's companion version object which for our case if a combination of Hybrid Logical Timestamp (8B) and unique client ID (string). Timestamp alone is not enough as it gives a very small (but not zero) chance of update collision. However when it comes to both serialization and in memory layout it's actually possible to optimize them.
Here we compress each cell version, by representing timestamp component as a delta from lowest known version timestamp ie. table first update - this could be be represented using upper 48 bits. It's enough to represent few thousands years of updates.
For the lower 16 bits, we use them to keep indexes to the list of cached client IDs - it should be enough to represent all unique peers.
class Versions() {
constructor(minTimestamp) {
/**
* The lowest known timestamp provided ie. at table creation.
* @type {number}
*/
this.minTimestamp = minTimestamp
/**
* List of all known clients.
* @type {string[]}
*/
this.clients = []
}
compress({timestamp, clientID}) {
// in JavaScript bitwise arithmetics work only up to 53 bit int
// it might be a good idea to use two 32bit ints instead
const delta = (timestamp - this.minTimestamp)
let i = this.clients.indexOf(clientID)
if (i < 0) {
i = this.clients.length
this.clients.push(clientID)
}
// we use 16 lowest bits for client surrogate
return (delta << 16) | i
}
compare(compressed1, compressed2) {
// clear bits used for client surrogate
const MASK = (1 << 16) - 1
const cmp = (compressed1 & ~MASK) - (compressed2 & ~MASK)
if (cmp === 0) {
// in over 99% cases the timestamps will never be equal
// but on the rare occassions when this happens we fallback
// to compare client IDs
const i1 = compressed1 & MASK
const i2 = compressed1 & MASK
if (i1 == i2) {
return 0 // clients are the same as well
}
if (this.clients[i1] > this.clients[i2]) {
return 1
} else {
return -1
}
}
return cmp
}
}
With this approach we only use 8 byte numbers per cell version (compared to entire JavaScript object before). For JavaScript they could be also further optimized by putting them onto specialized arrays like Uint32Array.
Comments