This time we're going to cover a new implementation of persistent key value store, using Conflict-free Replicated Data Types (CRDTs) to enable multi-process writes. Moreover, this approach enables shift of replication protocol from custom made gossip servers into passive replicated storage such as iCloud or Google Drive.
Why?
When you'll start developing systems which are dealing with synchronisation/replication, you'll eventually discover that doing this from scratch, at scale, is hard. That's why almost nobody does it this way: we use existing tech stacks which are doing it for us, sometimes going as far as changing our business requirements to their limitations.
One of the common problems in Conflict-free Replicated Data Types is that they were originally implemented as in-memory data structures. However, a practical use cases require not only new convergent/commutative set of actions, but also support for persistence and network to replicate changes to other users. Neither replication via central client/server nor peer-to-peer architecture is a simple task and requires extra operational effort to maintain such infrastructure.
Question is: could we use existing services to scale out our CRDTs? Many existing providers offer passive storage that could be used out-of-the-box as a medium for replication and persistence. Many of them have a freemium model (i.e. Google Drive or iCloud) that is generously offered along with their other associated services. Finally they may have come as self-hosted systems (network drives or SSH servers) that we can run ourselves if needed.
All things mentioned above share common property: they offer an API that could be abstracted into a subset of file system capabilities. iCloud/GDrive/Dropbox/OneDrive all offer a virtual directory, that is available even when offline and occasionally synchronised with cloud and other user devices when online. This is what we're going to use.
Why not Git?
When we're talking about replicating changes across multiple devices by elevating file system capabilities, this should sound very similar to Git. To reiterate quickly how git works:
Whenever you commit your changes to .git repository, these changes are summarised together into a single object (file). This file's name is a consistent hash of its own contents, which means that its immutable and cannot be further modified. Beside changeset, file also contains signature authenticating its author and a hash of the previous file change(s), that were its direct parent(s).
This basically means, that all we need is to detect new files that appeared in a (sub)directory since the last time we fetched the previous changes. This comes with few disadvantages:
- Every single change is a file with signature. While enough for explicit version control system commits - most of the users do way below dozen commits per day - CRDTs often require more fine-grained level of synchronisation: in collaborative text editors each key stroke is a change visible to others. We cannot afford to put them into separate signed files.
- Since every object is immutable and we use their content addresses to construct graph of changes, they cannot be squashed or compacted over time.
- Detecting a long history of changes in git often may require multiple hops to catch parent of a parent etc. What if these are not immediately available i.e. because underlying virtual file system (VFS) didn't replicate all changes or is doing it not in expected order?
- Some Git files (like
.git/HEAD) have their contents overridden on change, which may cause issues when edited concurrently by different processes and replicated by shared storage at the same time.
For these reasons we're going to use slightly different approach: our primary pattern is series of append-only files, which is easier and cheaper to track for continuous changes. We also won't cover digital signing of user changes: this process is inherently expensive to do over small changesets and prevents them from potential compaction. Well shortly discuss potential solution for auth problems along the way.
BitCask Architecture
Below we'll be describing an architecture of a CRDT-over-VFS approach, which proof of concept can be found on Github.
For our use case, we're going to provide a CRDT that works like a simple persistent key-value map (similar to how LMDB or RocksDB works) which enables multiple processes to concurrently modify any of its entries without blocking and merge these changes using last-write-wins strategy per each entry. We only cover minimum requirements: no transactions, compaction and advanced CRDT algorithms. Just to let you know: these are possible to implement.
For our implementation I'm going to use a modified BitCask architecture, which is very simple form of persistent KV store:
In BitCask primary keys are all stored in an in-memory index - which means that they cannot grow over the RAM size.
struct DbInner<D: VirtualDir> {
/// In BitCask architecture entries are stored in memory,
/// while their values are persisted on disk.
entries: DashMap<Bytes, DbEntry>,
/// Structure which keeps file handles to opened active sessions.
/// In some operating systems opening a file is an expesinve operation,
/// so we keep them open and track the numer of entries referencing them.
sessions: DashMap<Sid, SessionHandle<D::File>>,
/// Tracker used to check which session files have already been visited.
sync_progress: DashMap<Pid, ProgressTracker<D::File>>,
/// Unique identifier of a currently opened session belonging to this
/// process.
sid: Sid,
/// Root entry to a file system, where current Database data is being
/// stored.
root: D,
}
Our map is spanned across a directory structure - this directory could exist on a mounted drive ie. Google Drive installed on your operating system. In our proof of concept, virtual drive is hidden behind VirtualDir/VirtualFile traits, which expect following capabilities:
- Writer process must have full read, write and create file access to its own subdirectory.
- Readers must have at least read access to subdirectories of other processes for sync purposes.
- All files are written in append-only fashion.
- Seek API is required for:
- Random reads for
Db::getviaSeekFrom::Start(offset). It may also be used for incremental synchronisation. - Moving file cursor from random reads to end of file for append purposes via
SeekFrom::End(0). - Checking length of a file via
SeekFrom::Current(0).
- Random reads for
Technically these properties are not limited to a file system: we can implement our database over any API which satisfies at least these requirements.
We enable multiple processes to concurrently write to an overall map structure. Each process has its own globally unique identifier (Pid) that can be reused between process runs (sessions) as long as two different applications/devices are not trying to reuse the same Pid.
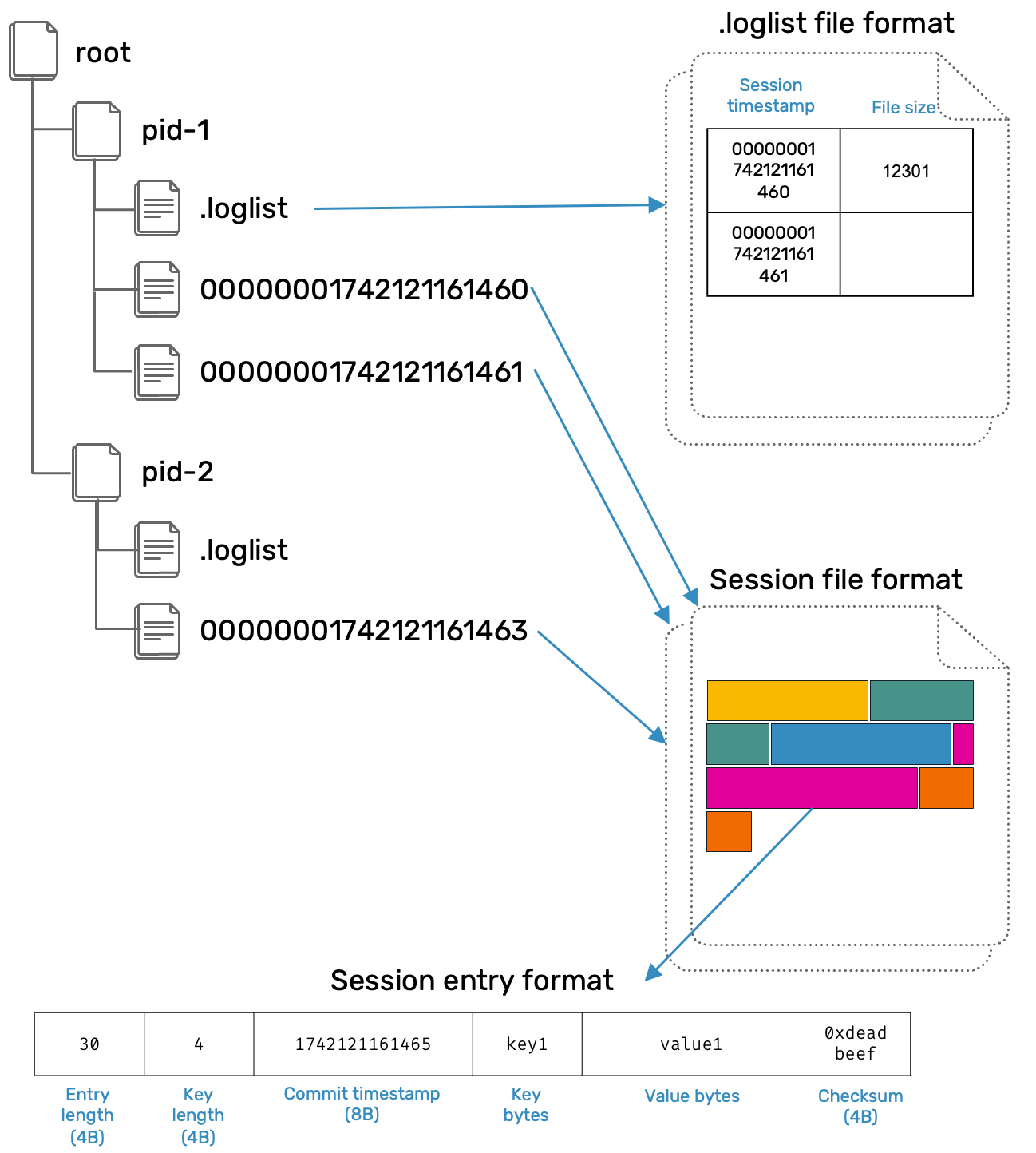
Each Pid is associated with its own subdirectory, that only this process can write to. For the synchronisation purposes, other processes can have read-only access for each others pid subdirectories at any time.
Each subdirectory can contain two kinds of files:
- A series of session files identified by an unsigned 64-bit integer timestamp.
- A single (per process)
.loglistfile used to inform others about created and currently running sessions.
Both of these file kinds are working in append-only fashion.
Session log files
Log files are directly related to BitCask data structure. Every change (insertion or deletion) is written as an entry into log file and then merged into in-memory key index:
Each entry contains following information:
- Entry starts with a total length of itself in bytes. It's useful to know it in advance to allocate necessary buffer to load entry's data from disk to memory.
- Length of the key in bytes. Value length is not mandatory: we'll be able to infer it.
- Timestamp when entry was committed. We'll use this for potential conflict resolution. In our implementation it's just a system clock value. For real purposes, you probably want something more reliable, like Hybrid Logical Clocks.
- Key byte string.
- Value byte string.
- Checksum confirming that no disk bit corruption happened. We verify checksums when we retrieve entry values from disk for
Db::getpurposes.
Whenever a process wants to delete given entry, we append it to session log as a new tombstone entry. For simplicity we identify tombstones simply as entries with empty values.
Each session is identified by Sid - a globally unique identifier that's a composite of its owner process id (Pid) and a timestamp when session was created.
Restoring the database state is a matter of reading all entries from all session files and merging them (using entry's commit timestamp). This process may be expensive and BitCask creators introduced so called hint files - which are basically snapshots of in-memory entry index used by BitCask - to speed up this process. However since it's not mandatory, for simplicity we'll omit it in our example.
Introduction of log list files
Another file type that we're going to use is .loglist file. This file is an append only history of sessions created by given pid:
Every entry in .loglist has up to 16 bytes and consist of:
- Timestamp of a session created by current process. We can use it to get session files.
- (Optional) size of a corresponding session file. We use it for two reasons:
- To mark that session has ended. Currently active sessions - the ones that are actively being written to - don't have corresponding session size set and are always listed at the end of
.loglistfile. Each process can have at most one active session at the time. - To verify if session file has not changed. Once session ends, we write its length to
.loglistfile and from that point onward this file is immutable. We can use length to check if nobody tried to tamper with it or if it's still being replicated by an underlying VFS.
- To mark that session has ended. Currently active sessions - the ones that are actively being written to - don't have corresponding session size set and are always listed at the end of
Whenever we want to open new session - i.e. at the application start - we generate new session timestamp, create a session file and append its timestamp (name) to a .loglist. Whenever we close session - i.e. because we're going to stop the application - we commit session size at the end of the .loglist file.
Log list file is useful to improve efficiency of our synchronisation procedure. Instead of scanning entire root directory of a database to find all unseen session files, we just need to lookup for:
- New
pidsubdirectories to discover if a new process writer has joined. - Read
.loglistfile of another process since last offset we read it to. This way we can check if there are any new session files that we haven't read before. - If last
.loglistentry has missing size, it means that it's being continuously being written to. Therefore we need to occasionally read that session file - again remembering the last offset we read it to.
Inserting and deleting entries
Once we covered theory, let's dive into practical implementation. We'll start from process of writing new entries:
// db.rs
async fn insert(&self, key: &[u8], value: &[u8]) -> crate::Result<()> {
let entry = {
let mut h = self.sessions.get_mut(&self.sid).unwrap();
let e = h.session.append_entry(key, value).await?;
h.inc_ref(); // increment number of entries using this session
e
};
// merge entry pointer with existing database state
if let Some(sid) = self.entries.merge(Bytes::copy_from_slice(key), entry) {
// ... cleaning of session file refecence counters
}
Ok(())
}
The process of appending entry is basically serialising an entry frame we described in session paragraphs and appending it to the end of a session file:
// session.rs
async fn append_entry(&mut self, key: &[u8], value: &[u8]) -> crate::Result<DbEntry> {
// move file cursor position to the end of the file
let file_position = self.file.seek(SeekFrom::End(0)).await?;
let timestamp = Timestamp::now();
// 4B total len + 8B timestamp + 4B key len + 4B checksum.
let entry_len = key.len() + value.len() + 20;
let mut buf = Vec::with_capacity(entry_len);
// write total length of the entry
buf.extend_from_slice(&(entry_len as u32).to_le_bytes());
// write key length
buf.extend_from_slice(&(key.len() as u32).to_le_bytes());
// write timestamp
buf.extend_from_slice(×tamp.to_le_bytes());
// write key
buf.extend_from_slice(key);
// write value
buf.extend_from_slice(value);
// write checksum
let mut crc = crc32fast::Hasher::new();
crc.update(&buf);
let checksum = crc.finalize();
let checksum_bytes = checksum.to_le_bytes();
buf.extend_from_slice(&checksum_bytes);
// construct marker used later to locate session file holding
// this entry and location of an entry itself within a file
let entry = DbEntry::new(
self.sid.clone(),
timestamp,
file_position,
key.len() as u32,
entry_len as u32,
);
// write serialized entry to the session file
self.file.write_all(&buf).await?;
Ok(entry)
}
Above we're just manually writing the buffer that we had preallocated. For real use case, you may want to use macros from Rust's zerocopy crate, which would let you build an inline structure and convert it back and forth straight into byte slice without any heap allocations necessary.
Eventually we merge the new entry into our in-memory index - just like mentioned in the beginning: we use the simplest last-write-wins strategy, but there's nothing stopping you from building more advanced algorithms. The session logs architecture described here matches principles of partially ordered log: we already went through operation-based CRDT variants on this blog in the past.
// db.rs
fn merge(&self, key: Bytes, entry: DbEntry) -> Option<Sid> {
match self.entry(key) {
Entry::Occupied(mut e) => {
let existing = e.get();
if entry > *existing {
// conflict resolution - keep the entry with the latest timestamp
let old = e.insert(entry);
Some(old.sid) // return the ID of the outdated entry
} else {
Some(entry.sid) // new entry is outdated one
}
}
Entry::Vacant(e) => {
e.insert(entry);
None
}
}
}
Above you can also catch a glimpse of session file management code. We'll mostly skip it in this blog post snippets, since they are not crucial for the algorithm itself. Just a short explanation: the process of opening file handles is a little bit expensive to be done every time we need to fetch a value for the key we want to read. For this reason when restoring the database state, we cache session files around and keep a reference counters of entries pointing to them (+1 if this is our current session). Once the counter hits 0, we're safe to dispose the file handle.
Reading entries
Reading entries is just as straight forward. We use a DbEntry in-memory structure to locate the session file and offset within it, that holds the actual value:
// db.rs
async fn get(&self, key: &[u8]) -> crate::Result<Option<Bytes>> {
let key = key.as_ref();
match self.entries.get(key) {
Some(e) => {
// open a session for an entry we found and read it
let mut h = self
.sessions
.session_entry(e.sid.clone())
.or_read(&self.root)
.await?;
let mut key = BytesMut::new();
let mut value = BytesMut::new();
h.session.read_entry(&*e, &mut key, &mut value).await?;
if value.is_empty() {
// see [Db::remove] - we treat no-value entries like tombstones
Ok(None)
} else {
Ok(Some(value.freeze()))
}
}
None => Ok(None),
}
}
async fn read_entry(
&mut self,
entry: &DbEntry,
key_buf: &mut BytesMut,
value_buf: &mut BytesMut,
) -> crate::Result<()> {
self.file.seek(SeekFrom::Start(entry.entry_offset())).await?;
self.next_entry(key_buf, Some(value_buf)).await?;
Ok(())
}
We describe next_entry method in a moment. The general idea here is that values are usually bigger than keys, therefore we don't keep them in memory. Instead we read them on demand. This behaviour matches the original BitCask design.
Database restore and synchronisation
Given the nature of our solution, restoration and synchronisation are solved by pretty much the same procedure. Two major differences are:
- Synchronisation doesn't have to read processes own subdirectory, since active database always keeps it in the most up-to-date state.
- Synchronisation doesn't have to read everything from scratch. We can just continue from the last session/offset we read up to, which is why we introduced
sync_progressmap in our database in the beginning. This doesn't require any extra logic for restoration, as it just starts with an empty sync progress.
First we sync by reading up all .loglist files in all subdirectories:
async fn sync(&self, is_recovering: bool) -> crate::Result<()> {
let subdirs = self.root.list_files();
pin!(subdirs);
while let Some(subdir) = subdirs.next().await {
let pid = Pid::from(subdir?);
if !is_recovering && pid == self.sid.pid {
// if we're syncing, not recovering after shutdown,
// we're always up-to date with ourselves
continue;
}
// check the last known sync progress for a given process
let mut tracker = match self.sync_progress.entry(pid.clone()) {
Entry::Occupied(mut e) => e.into_ref(),
Entry::Vacant(mut e) => {
let log_list = LogListFile::open_read(e.key().clone(), &self.root).await?;
let tracker = ProgressTracker::new(log_list);
e.insert(tracker)
}
};
loop {
match tracker.log_list.next_entry().await {
Ok(None) => break, // we reached the end of a log file
Ok(Some(e)) => {
let sid = Sid::new(pid.clone(), e.session_start);
self.sync_session(sid, e.size, &mut tracker).await?;
if e.is_latest() {
// the last entry of the log file is not committed,
// so we may need to return to it in the next sync round
break;
}
}
Err(err) => break,
}
}
}
Ok(())
}
If a new subdirectories appeared since last sync, we also add them to sync_progress and restore data they've modified. If the session is new to a local process, we start reading its entries
from scratch. Otherwise we keep last session file offset around and move its file cursor so that we skip entries which we already read:
async fn sync_session(
&self,
sid: Sid,
expected_size: Option<u64>,
tracker: &mut ProgressTracker<D::File>,
) -> crate::Result<()> {
// get the session file we want to sync with
let mut h = self
.sessions
.session_entry(sid.clone())
.or_read(&self.root)
.await?;
h.session.seek(SeekFrom::Start(tracker.current_offset)).await?;
let mut key_buf = BytesMut::new();
loop {
match h.session.next_entry(&mut key_buf, None).await {
Ok(entry) => {
tracker.current_offset += entry.total_len as u64;
let key = key_buf.clone().freeze();
// try to merge the entry we read
match self.entries.merge(key, entry) {
// ... cleaning of session file refecence counters
}
}
Err(err) if err.kind() == ErrorKind::UnexpectedEof => {
// we reached the end of a session file
break;
}
Err(err) => return Err(err.into()),
}
}
drop(h); // DashMap's RefMut doesn't allow us to drop the value
// ... drop session handle if there are no entries pointing to it
Ok(())
}
Once we put file cursor position at valid offset we can read it by reversing the steps we did for write.
// session.rs
async fn next_entry(
&mut self,
key_buf: &mut BytesMut,
value_buf: Option<&mut BytesMut>,
) -> crate::Result<DbEntry> {
let start_len = self.file.stream_position().await?;
let mut header = [0u8; 16]; // 4B total len + 8B timestamp + 4B key len
self.file.read_exact(&mut header).await?;
let mut crc = crc32fast::Hasher::new();
crc.update(&header);
// read total length
let total_len = u32::from_le_bytes(header[0..4].try_into().unwrap()) as usize;
// read key length
let key_len = u32::from_le_bytes(header[12..16].try_into().unwrap());
// read timestamp
let timestamp = Timestamp::from_le_bytes(header[4..12].try_into().unwrap());
// read key
key_buf.clear();
key_buf.resize(key_len as usize, 0);
self.file.read_exact(&mut key_buf[..]).await?;
crc.update(&key_buf);
// read value
let value_len = total_len - key_len as usize - 20;
// only verify checksum if we need to read a value
let mut verify_crc = true;
if let Some(value_buf) = value_buf {
value_buf.clear();
value_buf.resize(value_len, 0);
if value_len > 0 {
self.file.read_exact(&mut value_buf[..]).await?;
crc.update(&value_buf);
}
} else {
verify_crc = false;
// move value_len forward
if value_len > 0 {
self.file.seek(SeekFrom::Current(value_len as i64)).await?;
}
};
// read checksum
let mut checksum = [0u8; 4];
self.file.read_exact(&mut checksum).await?;
let checksum = u32::from_le_bytes(checksum);
if verify_crc && checksum != crc.finalize() {
Err(Error::new(ErrorKind::InvalidData, "checksum mismatch"))
} else {
Ok(DbEntry::new(
self.sid.clone(),
timestamp,
start_len,
key_len,
total_len as u32,
))
}
}
In our snipped, buffer used for reading values is optional: we use it when reading values via Db::get, but it's not necessary for restoration. If we didn't read it, we cannot verify its checksum anymore, but it's not necessary for restoring the database state, since:
- Entry may have been overridden later, so the fact that it's malformed may not affect a current state of the system.
- Malformed entry may never be read, so we don't want to render our database unusable because of it. This would matter however if we cared about transaction support and one of our entries became unreadable.
Skipping values using file.seek is double edged sword. Depending on the VFS implementation and size of the value itself it may not be cheaper than just reading through it.
Keep in mind, that if you use API that only allows efficient search by prefix, you may decide to put all .loglist files in the same dedicated space instead of keeping them scattered over process subdirectories.
What VFS gives us for free?
Nice thing about reusing virtual file system, is that we can leverage existing infrastructure to cover both persistence and network replication in one go and make it another company problem (for better or worse), instead of having to build it for ourselves.
Another common issue with CRDTs is permission model. While we didn't cover it in our example, we built our database directory structure in a way that could make use of permission model of underlying operating system or service providers:
- Each process has its own subdirectory that only it is allowed to write to.
- We can control a read access for changes made by other processes by giving read-only access to their
pidsubdirectories.
A natural downside of using passive storage for replication is that our sync latency is constrained to the speed of the disk sync daemon of provider we're using + the refresh rate interval we configured. If you want to observe other users changes in realtime, this is probably not a solution for you.
What's next
One of the important topics, that were also not covered here, is about session file compaction. With many changes over time, our database directory can easily get filled with massive amount of outdated information. These are addresses by traditional database architectures ie. LSM tree compaction strategies, and with a bit of caution can be applied here.
Technically each process is free to compact its own finished sessions together into a new session file - since every entry individually contains enough data to correctly perform merge process - thanks to timestamps which are independent from session start times or their position within the session files. Only issue is that processes cannot perform compaction on behalf of another process and is limited only to its own changes.
Another thing we skipped is transaction support, present in most KV stores. Enough to say, it's possible here. I.e. we can extend our session log entries to keep information if given entry is the last one in committed transaction (similar to how SQLite Write-Ahead Log frames work), store entries changed within the same transaction aside and only merge them after commit entry has been received. We can also use existing timestamps (again you should prefer Hybrid Logical Clocks for that goal) as a form of transaction identifiers when necessary. Unlike usual transactions, CRDTs by their very nature don't require aborts on conflict detection, so it's a non-issue here.
Summary
There's a variety of options and possible extensions to our example, but the main piece stays the same: we've build a persistent key-value store, constructed in a way which enables its conflict-free replication over the existing disk ⇔ cloud synchronisation mechanisms. This way we can elevate well known providers and their scaling capabilities instead of writing and maintaining our own.
Comments