In this blog post we'll cover how systems form clusters, what clusters actually are and what are their responsibilities. We'll also present different protocols responsible to serve the needs of the clusters with a various tradeoffs associated with them.
To make this blog post a bit more practical, we'll also go in depth of one of the membership protocols - known as under SWIM acronym - from theoretical standpoint up to example implementation in F#.
What clusters are all about
From a user perspective, cluster is supposed to serve as an illusion of a "single machine" and keep it safe from all of complexity coming from communicating with - usually dynamically changing - network of interconnected servers.
As it turns out, there's a multitude of protocols and responsibilities that services being a part of cluster need to solve to maintain that illusion. Going bottom-up, here are some of the questions our cluster usually needs to know how to answer for:
- How to join the cluster? Usually when we have a new server node, which we want to join to the cluster, it needs to know how to communicate with another node that's already part of the cluster itself. Where can it find that information? It's the question that needs to be answered:
- The simplest trick is to provide a static list of contact points as a configuration parameter provided at the start of new service.
- Another way is to use 3rd party service (like database, Consul, etcd or ZooKeeper) to serve as a node registry. Our cluster usually doesn't live in vacuum, and sometimes we can reuse other already established services for our advantage.
- In some situations, we could leverage capabilities of lower layers - like Kubernetes DNS service or mDNS - that are specific to a host environment to dynamically discover other devices living in the same network.
- How do we know what other nodes are part of the cluster? This is area of so called membership protocols on which we'll focus in second part of this blog post. In dynamic clusters it's usually done by keeping track of a active discovered nodes, then updating and gossiping them once a node joins/leaves the cluster. A lot of decisions here depend on deployment scenario - services forming a cluster within the same datacenter have different characteristics from eg. meshes of mobile devices.
- In cases of common backend services hosted in the same datacenter, each node keeps a full information about the state of the cluster. This is how protocols like SWIM operate.
- Other membership protocols (like HyParView) enable to have only partial view on the cluster. This is preferable in cases when our cluster operates on much higher scale eg. thousands of nodes (usually most clustered services living in datacenters don't reach over dozens-to-hundreds of servers).
- How do we send messages from one node to another? This usually is also related to a membership protocol.
- Most datacenter-oriented systems can make conservative assumption that every node in the system can connect to every other node, forming (potentially) a fully connected mesh.
- In other scenarios, we need to take into account that some of the nodes may not be able to connect to others - because of the underlying network characteristics. While the most common case of that is client-server architecture, when we're talking about cluster protocols, often more advanced scenarios need to be applied (as we mentioned, "server" itself is not a single entity).
- How do we detect dead nodes? Also known as failure detection. The oldest known trick in that area is a simple exchange of PING 🡘 ACK messages within expected timeout boundaries every now and then, or simply expecting every connection to send a heartbeat message within given time interval.
- Heartbeats are often implemented directly into transport layer (like TCP), sometimes we're able to piggyback failure detector directly on top of it. Downside of that solution is that while transport layer itself is responsive - because it's usually managed by underlying OS - our application layer could in fact be not (eg. because it hangs deadlocked indefinitely). Another thing is that temporal failure of network connection doesn't has to mean, that node won't try to restart it and continue to work.
- More often, membership protocols promote their own heartbeat algorithms. What's worth noticing here, missing heartbeat doesn't necessarily mean, that our node is dead. It could as well be overwhelmed with serving other incoming requests. Modern algorithms like Phi accural failure dector or Lifeguard (an extension to SWIM protocol mentioned above) take that behavior into account.
These are the most basic questions cluster needs to know how to answer. We could call it a layer 0 of any cluster. The main part of this blog post will cover how to implement protocol addressing these issues. On top of it, there are many other higher level features, aiming to solve problems like:
- How can we detect/respond to periodic network partitions? A problem often known as split-brain scenario. It comes from basic observation that it's not possible to differentiate dead node from unresponsive one over network boundary. It can lead to very risky situations, like splitting our cluster in two, each one believing, it's the only one alive and causing data inconsistency or even corruption. There's no one simple cure for that, that's why some systems (like Akka.NET split brain resolvers) offer different strategies depending on the tradeoffs, that we care for.
- How different nodes can reason and decide about the state in the cluster? This case is usually common in systems that are responsible for data management (like distributed databases). Since nodes must be able to serve incoming requests, sometimes they may possibly run into making conflicting decisions about the state of the system. Without going into too much details, two generic approaches two this problem are:
- Avoiding conflicts, which usually assumes that nodes must establish consensus about state of the system before committing to their decisions. It usually requires establishing (and maintaining) some leader among the nodes, synchronizing via quorum of nodes or combination of two. This is area of popular protocols such as Raft, ZAB or Paxos.
- Resolving conflicts which accepts the possibility of state conflict to appear - mostly as a tradeoff happening in face of long latencies or periodically unreachable servers - but enriches it with enough metadata so that all nodes individually can reach the same conclusion about the result state without need of consensus. This is a dominant area of Conflict Free Replicated Data Types, which you could read about eg. in a blog post series published here.
- How to route requests to a given resource inside of cluster? The state of our system usually consists of multiple addressable entities - which are often replicated for higher availability and resiliency. However usually the entire state is too big to fit into any single node. For this reason it's often partitioned all over the cluster dynamically. Now this begs a question: how to tell, which node contains an entity identified by some virtual key?
- Naive approach would be to ask some subset of nodes in hope that at least one of them will have a data we hope for. Given cluster of N nodes and entity replicated R times, we should be able to reach our resource after calling (N/R)+1 nodes.
- More common way is to keep a registry having an information about current localization of every single entity in a system. Since this approach doesn't scale well, in practice we group and co-locate entities together within partitions and therefore compress the registry to store information about entire partition rather than individual entity. In this case resource ID is composite key of (partitionID, entityID). This is how eg. Akka.Cluster.Sharding or riak core works. Frequently some subset of hot (frequently used) partitions may be cached on each node for to reduce asking central registry or even the registry itself may be a replicated store.
- We could also use distributed hash tables - where our entity key is hashed and then mapped into specific node that is responsible for holding resources belonging to that specific subset of key space (a range of all possible hash values). Sometimes this may mean, that we miss node at first try eg. because cluster state is changing, and more hops need to apply. Microsoft Orleans and Cassandra are popular solutions using that approach.
As you can see, even though we didn't asked all questions, there's already a lot of things happening here and the same problems may be solved with different approaches depending on the tradeoffs our system is willing to take.
While there's a chance to make a separate article about each of these in the future, today we'll focus solely on a SWIM - used in systems such as Consul and hugely popularized over last few years - as it's easy to implement for a good start. To improve its resiliency and reduce false positive failure detection, checkout this talk about Lifeguard - a set of extensions and observations about original SWIM protocol.
SWIM protocol - theory
Since SWIM is responsible for membership management, we need to consider few crucial scenarios:
- New node wants to join the cluster - how to make that happen and how to inform other nodes in the cluster about that event?
- Node wants to leave the cluster gracefully - how to gossip that information?
- Node was abruptly terminated or cannot be reached any longer. How to detect that an inform others about the fact?
While first two cases are pretty easy, all of the complexity comes with the third case. We need to discover if node cannot be reached, but that's not enough - since temporary network failures may happen even inside the same datacenter, they usually get healed fairly fast. We don't want to panic and throw the node out of the cluster just because we couldn't reach it in split second. This would lead to very shaky and fragile cluster.
We've already mentioned heartbeat mechanism - every now and then we're going to send a PING message to other random node. This node is expected to answer with ACK before expected timeout. Easy.
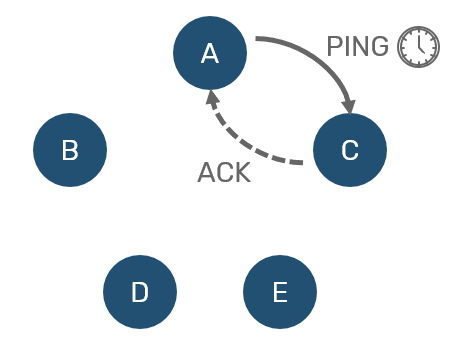
Now, what happens if node didn't respond under timeout? As we said, we don't want to overreact. So we don't consider this node dead yet. Instead we consider it to be suspect and inform others about our suspicion. Other nodes that received suspect gossip expect it to be confirmed within specified timeout - otherwise they will consider it a hoax, and remove node from their suspected list.
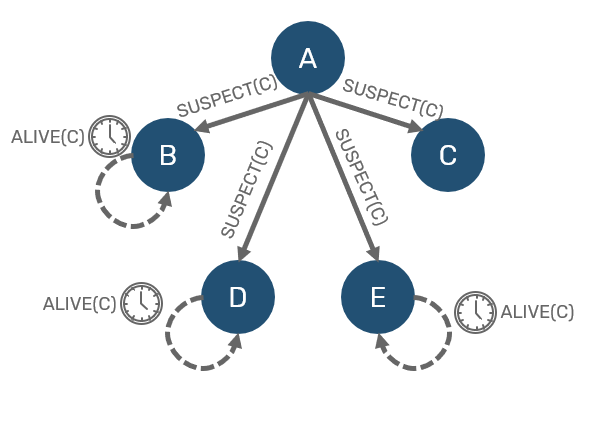
Now all we need is confirmation - in order to do so, we need to ask someone else for verification. So we're going pick another unsuspected node and ask it to ping suspect for us (this request is known as PING-REQ). Now if that mediator managed to receive ACK from the suspect, we know that node is alive, just our network connection was severed for some reason:
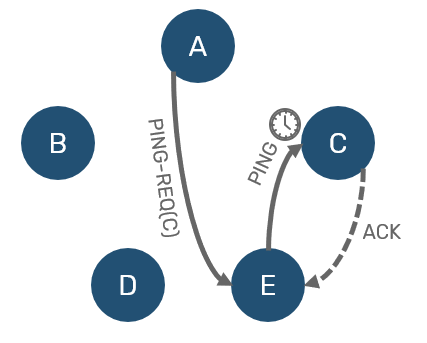
On the other side, if our mediator didn't received ACK either, we now have two-hand verification that node is unresponsive for significant time frame - therefore it can be confirmed as dead to everyone.
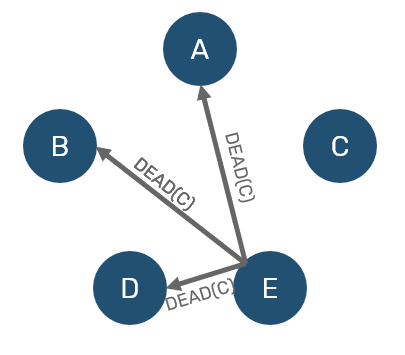
Of course this doesn't mean that node is indeed dead - one escape mechanism is that if suspect will get a suspect notification about itself, it can override it by broadcasting alive message. There maybe different reasons, why suspect didn't respond on time: it may be too occupied (either by backlog of other requests or eg. stop-the-world garbage collection of underlying VM). It may also happen, that our network have split the cluster apart - this phenomenon is known as a split-brain.
Ultimately there's no way to ensure 100% reliable failure detection. We're just trading reasonable ratio of false failure and how quickly can we detect node as dead - usually these two goals work against each other. In terms of SWIM, I again recommend to lookup for Lifeguard, which addresses some of the mentioned scenarios. However we'll not cover it in our implementation below to keep it succinct.
SWIM protocol - implementation
Now, we're going to actually implement that protocol. In order to do so we're going to apply some simplifications - we'll do so to make protocol easier to comprehend:
- In general to associate specific request/response messages, we should use some form of sequence numbers. This can result in scenario, when A sends PING1 request to B for which is responds with ACK1, some time later A sends another PING2 to B and receives ACK1 back - the problem was that it cannot tell which PING this message was acknowledgment for. This kind of situation is very rare, but not impossible. If may also lead to "resurrecting" dead nodes.
- While we're going to piggyback gossip on top of pings - like the paper suggests - we're simply gossip entire membership state every time. It's not the most optimal way, but it'll work good enough.
PS: Other way of avoiding sending entire state with every gossip is to compute consistent hash of current node membership view and put that hash inside of ping instead of full view. This way our PING will carry just a hash value, which responder may compare with hash of its own state. Only if hashes differ (in clusters with small churn of nodes most of the time they don't), we're putting membership state on top of ACK.
The code used here is available in this gist, which I recommend to use, as we'll not cover everything here.
Prerequisites
Since we don't want to deal with all complexities of node-to-node communication, we'll just build a model on top of abstractions, that will let us evaluate the algorithm without derailing into solving other problems. The basic prerequisites here are:
- A transport layer that will just let us send message to another (possibly remote) endpoint. We don't want to deal with managing network connections or serialization details.
- An agent accessible behind the endpoint, able to serve multiple requests and change its state in thread safe manner.
- A timer capability to asynchronously trigger an event after specified timeout period.
For these reasons, I'm going to use Akka.NET/Akkling and model our nodes using actors living in the same process. You can easily adopt it to different actor systems connected over Akka.Remote. We keep this as a training exercise - in practice if you want to use clusters in akka, you already have entire ecosystem built on top of Akka.Cluster, which handles membership - and other problems mentioned in introduction - for you.
Our actor will be created by providing it an initial list of contact points: these are the endpoints known to be part of the cluster:
open Akkling
use sys = System.create "swim-cluster" <| Configuration.parse config
// In this example `a` and `b` are actor refs for other
// SWIM cluster members living on other nodes.
let c = spawn sys "node-b" <| props (Swim.membership [a; b])
In order to create that actor first we need to deal with a joining process. The idea is that we'll try to pick endpoints from the provided list (it corresponds to seed node addresses in Akka.Cluster ) and send a Join request to them. If cluster node actor will receive such request, it's obliged to accept it by sending Joined response to ALL cluster members (including requester).
In case when Joined wouldn't arrive eg. because we misconfigured our cluster and other endpoint couldn't be reached, we wait for some time and try another node from the list. This could be represented as:
let membership (seeds: Endpoint list) (ctx: Actor<_>) =
let state =
{ Myself = { Endpoint = ctx.Self }
Active = Set.empty
Suspects = Map.empty }
(* rest of the actor code... *)
let rec joining state cancel = actor {
match! ctx.Receive() with
| JoinTimeout [] -> return Stop // failed to join any members
| JoinTimeout (next::remaining) ->
next <! Join state.Myself
let cancel = ctx.Schedule joinTimeout ctx.Self (JoinTimeout remaining)
return! joining state cancel
| Joined gossip ->
cancel.Cancel() // cancel join timeout
return! becomeReady state gossip
| Join peer when peer = state.Myself -> // establish new cluster
cancel.Cancel() // cancel join timeout
return! becomeReady state (Set.singleton state.Myself)
| _ -> return Unhandled
}
match seeds with
| [] -> becomeReady state (Set.singleton state.Myself)
| seed::remaining ->
seed <! Join state.Myself
let cancel = ctx.Schedule joinTimeout ctx.Self (JoinTimeout remaining)
joining state cancel
After receiving the Joined request actor associates itself as a operating member of the cluster, ready to work. From now on it will trigger itself to periodically check if others remain responsive:
let merge gossip state = { state with Active = state.Active + gossip }
let becomeReady state gossip =
ctx.Schedule pingInterval ctx.Self NextRound |> ignore
ready (merge gossip state)
As mentioned before, in this case gossip is just a full set of active cluster members, while ready is actor behavior used for standard cluster activities:
let rec ready state = actor {
match! ctx.Receive() with
// other message handlers
| _ -> return Unhandled
}
Since we covered joining procedure from requestor side, let's do that for operating cluster member as well:
match! ctx.Receive with
| Join peer ->
let gossip = Set.add peer state.Active
let msg = Joined gossip
gossip
|> Set.remove state.Myself
|> Set.iter (fun peer -> peer.Endpoint <! msg)
return! ready { state with Active = gossip }
| Joined gossip -> return! ready (merge gossip state)
// other handlers
As we said, once new member tries to join, we simply update our active members state and gossip it to all other members in Joined message, so they could update it as well.
Now, let's cover pinging process. First we mentioned that we want to trigger our member every now and then - you could already see that when we scheduled NextRound event in becomeReady function. Now how it will work? We're going to pick one node at random - other than current one and not being suspected (suspects are nodes that didn't reply to pings on time) - and send a Ping request to it. In the meantime we also schedule a timeout for that request to complete:
let pick peers =
match Set.count peers with
| 0 -> None
| count ->
let idx = ThreadLocalRandom.Current.Next count
Some (Seq.item idx peers)
let ready state = actor {
match! ctx.Receive() with
| NextRound ->
ctx.Schedule pingInterval ctx.Self NextRound |> ignore
let suspects = state.Suspects |> Map.toSeq |> Seq.map fst |> Set.ofSeq
let others = (Set.remove state.Myself state.Active) - suspects
// pick one member at random, other than self and not marked as suspected
match pick others with
| None -> return! ready state
| Some peer ->
// send Ping request to that peer and schedule timeout
peer.Endpoint <! Ping(state.Active, ctx.Self)
let cancel = ctx.Schedule pingTimeout ctx.Self (PingTimeout peer)
let skipList = Set.ofArray [| state.Myself; peer |]
return! ready { state with Suspects = Map.add peer (cancel, WaitPingAck skipList) state.Suspects }
| Ping (gossip, sender) -> // reply to incoming ping right away
sender <! PingAck(state.Myself, state.Active)
return! ready (merge gossip state)
// other handlers
}
Here we're using our suspects map to keep track of timeout cancellation and skip list. What's a skip list? We'll cover it soon. As we mentioned, when PingAck doesn't arrive on time, we're going to pick another member (at random) and ask it to ping our suspect for us using PingReq message. This way we try to mitigate risk of false negatives in our failure detection algorithm:
let ready state = actor {
match! ctx.Receive() with
| PingReq (suspect, gossip, sender) ->
let cancel = ctx.Schedule indirectPingTimeout ctx.Self (PingTimeout suspect)
suspect.Endpoint <! Ping(state.Active, ctx.Self)
return! ready { merge gossip state with Suspects = Map.add suspect (cancel, WaitPingReqAck) state.Suspects }
// other handlers
}
This time it's our indirect node, which sends a Ping request, along with scheduling a PingTimeout in case, when it won't arrive on time. As you might notice this member also will setup its suspect state, however this time using different status (without any skip list). Now what happens, when PingTimeout has happen? As we've seen, in this implementation it's used in different contexts:
let ready state = actor {
match! ctx.Receive() with
| PingTimeout suspect ->
match Map.tryFind suspect state.Suspects with
| Some (_, WaitPingReqAck) -> return! ready (leave suspect state)
| Some (_, WaitPingAck skipList) ->
let peers = state.Active - skipList
match pick peers with
| Some other ->
other.Endpoint <! PingReq(suspect, state.Active, ctx.Self)
let cancel = ctx.Schedule pingTimeout ctx.Self (PingTimeout suspect)
return! ready { state with Suspects = Map.add suspect (cancel, WaitPingAck(Set.add other skipList)) state.Suspects }
| None -> return! ready (leave suspect state)
| _ -> return Unhandled
// other handlers
}
First we try to find our suspect on the list of already suspected nodes, which can have several different outcomes:
WaitPingReqAckstatus marks a timeout related to ping made of behalf of another node. In this case it means, that both nodes couldn't reach the suspect. This gives us fairly strong proof that node is dead an can be removed from cluster.WaitPingAckstatus marks situation when node send aPingand didn't respondPingAck. But why is this case so complex. One of the things, that weren't mentioned by SWIM protocol authors is what happens then we sendPingReqto get a confirmation by another node, but it didn't respond as well? Treats like that are great, as they let us feel the difference between reading papers for fun and actually putting them into practical use. In this case we add another node that we didn't asked so far (using skip list to mark already asked nodes, suspect and current member) and ask it again. Once there will be no other node to ask on our behalf we must consider our suspect to be dead.
The 2nd point is fairly conservative choice, which may mean that when our node was severed from the rest of the cluster by eg. network split, it may take considerable amount of time to detect unreachable nodes.
Now as paper suggested, when a node didn't PingAcked on time, it becomes Suspected and that fact becomes broadcasted among all nodes. What's kinda interesting here, is that this gives suspect a second chance to stand for itself - if a suspect will be informed that it is suspected, it can "scream" it's Alive, this way denying false rumor:
let ready state = actor {
match! ctx.Receive() with
| Suspected suspect when suspect = state.Myself -> // false rumor
(Set.remove state.Myself state.Active)
|> Set.iter (fun peer -> peer.Endpoint <! Alive state.Myself)
return! ready state
| Suspected suspect ->
let cancel = ctx.Schedule suspicionTimeout ctx.Self (Alive suspect)
match Map.tryFind suspect state.Suspects with
| None -> return! ready { state with Suspects = Map.add suspect (cancel, WaitConfirm) state.Suspects }
| _ -> return! ready state
// other handlers
}
When other members received a rumor about their peer being Suspected, they're going to add it to their suspects list... however they expect the rumor to be confirmed within suspicion timeout, otherwise it will be put back Alive (see scheduled message). Alive simply means cancel all ongoing timeouts and remove member from suspected lists.
let ready state = actor {
match! ctx.Receive() with
| Alive peer ->
match Map.tryFind peer state.Suspects with
| None -> return! ready state
| Some (cancel, _) ->
cancel.Cancel()
return! ready { state with Suspects = Map.remove peer state.Suspects }
// other handlers
}
Another thing not covered in paper is situation when same node was notified about suspected node from several different peers. Can we eagerly consider it dead? Here, we conservatively won't do that: number of suspicions doesn't matter, as node may be unreachable only for of a moment, and during that time it was pinged from different places.
Now, we still didn't cover how to handle PingAck response itself. Again, it depends on who received it:
- In happy case scenario - when one sends
Pingrequest and another one replies withPingAck, we just remove it from list of suspects and call it done. - In case of acknowledgement being send to node who was asked on another's behalf, we also need to broadcast
Alivemessage to others in order to deny - now confirmed to be false -Suspectedrumor send by original node.
let ready state = actor {
match! ctx.Receive() with
| PingAck (who, gossip) ->
match Map.tryFind who state.Suspects with
| None -> state
| Some (cancel, status) ->
cancel.Cancel()
let newState = { merge gossip state with Suspects = Map.remove who state.Suspects }
match status with
| WaitPingReqAck ->
// notify everyone that actor is alive and no longer suspected
Set.remove newState.Myself newState.Active
|> Set.iter (fun peer -> peer.Endpoint <! Alive who)
| _ -> ()
return! ready newState
| _ -> return! ready (merge gossip state)
// other handlers
}
The last message type that was mentioned but remains untouched up to now, is Left. It can be used by any member leaving the cluster to leave it gracefully - which btw. you should always if possible in order to stabilize the cluster as fast as possible (read: don't shutdown your cluster servers by killing the process!). It is also send as a confirmation of unresponsiveness in case when PingReq was not replied on time.
let leave peer state =
let active = Set.remove peer state.Active
Set.remove state.Myself active
|> Set.iter (fun peer -> peer.Endpoint <! Left peer)
{ state with Suspects = Map.remove peer state.Suspects; Active = active }
let ready state = actor {
match! ctx.Receive() with
| Left peer ->
match Map.tryFind peer state.Suspects with
| None -> return! ready { state with Active = Set.remove peer state.Active }
| Some (cancel, _) ->
cancel.Cancel()
return! ready { state with Active = Set.remove peer state.Active; Suspects = Map.remove peer state.Suspects }
// other handlers
}
Closing thoughts
Here we created a simple implementation of SWIM membership protocol. For that, we used F# layer on top of Akka.NET library: I think it also presents how straightforward it is to build protocols and state machines using actor programming paradigm, while keeping it easy to reason about. We also presented shortly different cluster features - some of which might be interesting as topics for future blog posts.
Comments