Today we're going to jump into LSeq - one of the famous text-editing conflict-free replicated data types we briefly introduced in the past blog posts. This time we're aiming for fixing one of the popular issues that this algorithm struggles with. We're going step by step over popular existing implementation, problem statement and our novel proposed solution.
First, let's summarize the general approach to how all conflict-free replicated lists work. When inserting a new element, we create an immutable unique identifier for that element and keep it together with the metadata that describes relative placement of that element and its neighbours. In this blog, we already described several different algorithms implementing this approach:
- RGA and YATA algorithms create unique identifiers as Lamport clocks (combination of unique peer ID and some sequence number). Additionally inserted elements also keep information about their original neighbour element ids at the moment of insertion, that will be used to determine placement and conflict resolution.
- LSeq doesn't store the neighbour information. Instead an inserted element ID (here we'll call is a fractional index) is generated as an unbounded-length sequence in such a way, that it's lexically higher than its left neighbour and lower than the right one.
The fact that LSeq doesn't use adjacent elements as points of reference comes with several positive and negative aspects. One of the most common issues - which is one of the reasons why LSeq fell from grace and is no longer used for most of the collaborative text editing systems nowadays - is related to interleaving problem. Today, we're going to present this issue and also show a novel approach on how to solve it.
Here, we'll be referring to code, which you can see in this Github repository. We'll be using a fairly simple LSeq implementation with two different fractional index implementations: a standard one used to showcase interleaving issue and one which solves this problem.
#[derive(Debug, Clone, PartialEq, Eq, Ord, PartialOrd, Hash)]
pub struct LSeq<K, V> {
peer: PeerId,
entries: BTreeMap<K, Option<V>>,
}
impl<K, V> LSeq<K, V>
where
K: FractionalIndex,
{
pub fn insert_range<R>(&mut self, index: usize, range: R)
where
R: IntoIterator<Item = V>,
{
let mut iter = self.entries.keys();
// pick starting left and right neighbours
let mut left = if index > 0 {
iter.nth(index - 1).cloned()
} else {
None
};
let right = iter.next().cloned();
for value in range {
// generate fractional index in between left/right
let key = K::new(self.peer, left.as_ref(), right.as_ref());
self.entries.insert(key.clone(), Some(value));
// set newly generated key as a new left neighbor for the next
// element
left = Some(key);
}
}
}
Our LSeq is simple. It's just a sorted tree, where keys are fractional indexes and values are options (None elements are used for deletion/tombstoning). Inserting multiple elements is just a recursive process of generating fractional index between left and right element of the given index position. It's may seem expensive to store i.e. individual characters this way, but we'll cover that problem in the future.
Interleaving
While we already glossed over the LSeq interleaving issue in the past, let's explain it in detail. This issue happens when two users will start inserting elements (eg. characters) at the same cursor position concurrently, messing with each others changes.
Before we continue, let's first explain the details of a standard fractional index generation:
#[derive(Clone, PartialEq, Eq, Ord, PartialOrd, Hash)]
pub struct NaiveFractionalIndex {
sequence: Vec<u8>,
peer_id: PeerId,
}
impl FractionalIndex for NaiveFractionalIndex {
fn new(peer_id: PeerId, left: Option<&Self>, right: Option<&Self>) -> Self {
let lo = left.map(|l| l.sequence.as_slice()).unwrap_or(&[0x00]);
let hi = right.map(|r| r.sequence.as_slice()).unwrap_or(&[0xff]);
let mut sequence = Vec::new();
let mut i = 0;
let mut diffed = false;
while i < lo.len() && i < hi.len() {
let lo_byte = lo[i];
let hi_byte = hi[i];
if hi_byte > lo_byte + 1 {
// there's enough space between lower and higher segment
// to insert a new unique segment
sequence.push(lo_byte + 1);
diffed = true;
break;
} else {
// continue fractional index creation by copying lower segment byte
sequence.push(lo_byte);
}
i += 1;
}
// one of the fractional keys reached its end.
// Substitue them with MIN/MAX segment values.
while !diffed {
let lo_byte = lo.get(i).copied().unwrap_or(0x00);
let hi_byte = hi.get(i).copied().unwrap_or(0xff);
if hi_byte > lo_byte + 1 {
sequence.push(lo_byte + 1);
diffed = true;
} else {
sequence.push(lo_byte);
}
i += 1;
}
Self { sequence, peer_id }
}
}
The code above creates a left-side adjacent fractional index. We basically build it as the smallest byte sequence that's higher than the left neighbour and lower than the right. Now: if two peers could insert the element at the same position at the same time, so the generated fractional index would be the same. In order to keep our indexes unique, we also append peer_id to differentiate them is such cases.
This implementation however comes with following issue:
let mut a = LSeq::new(A);
let mut b = LSeq::new(B);
// initial state of the document
a.insert_range(0, "H !".chars());
a.insert(1, 'I');
// synchronize changes to both clients
a.merge(b.clone());
b.merge(a.clone());
// make changes concurrently on both clients
// at the same cursor position
a.insert_range(3, "mom".chars());
b.insert_range(3, "dad".chars());
// synchronize changes again
a.merge(b.clone());
b.merge(a.clone());
// show the text after sync
a.to_string(); // "HI mdoamd!" - characters are interleaved!
This example can be illustrated by the diagram below:
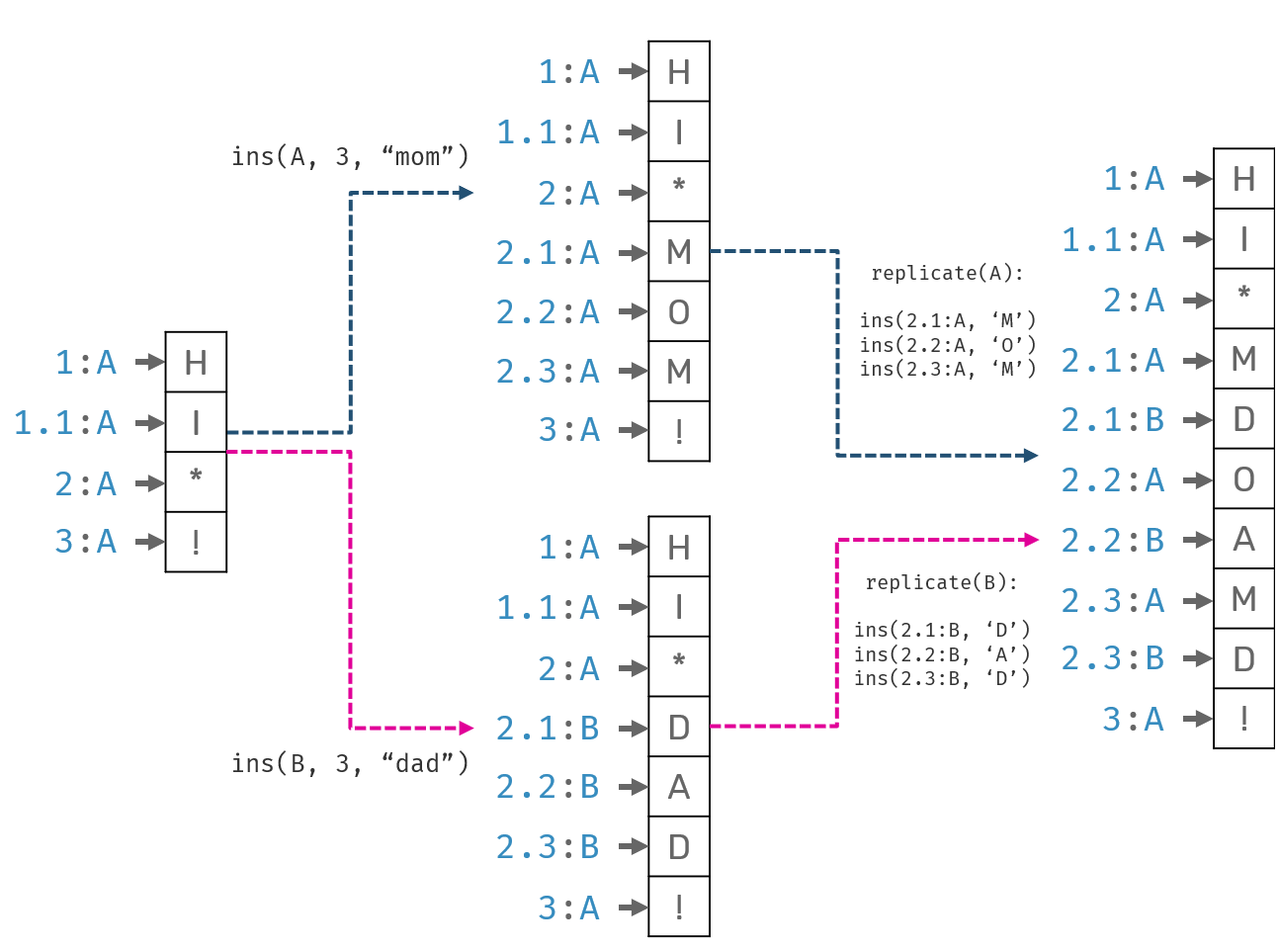
While after sync the state on both peers is the same - therefore: algorithm is "technically correct" - from user perspective having chunks of text from two users got mixed together. Sometimes it's ok, but for text editing it could be bad experience: the only thing user can do is to delete entire scope of a conflict and start over again.
This issue doesn't originally happen in other algorithms like RGA or YATA, since they are using information about their neighbours to correctly place themselves in a relation to previously written characters. Since LSeq doesn't hold that information - elements don't keep dependencies to each other - it doesn't know how to properly maintain continuity between characters inserted sequentially by the same peer. How can we fix it?
Fixing the interleaving issue
First, let's define what's the source of a problem: since our fractional index generation algorithm is deterministic, both peers produced the same sequences of bytes. Once suffixed with peer ID for uniqueness, it caused the characters to mix perfectly, which is an undesirable behaviour.
In the past one of the proposed ways to mitigate this issue was to build fractional indexes by adding randomness in byte sequence generation (basically random(lo_byte, hi_byte)). This however doesn't fix the issue - only reduces it. Moreover, we would no longer be able to infer if elements were inserted sequentially.
In our approach we're going to change what fractional indexes are made of: instead of operating on bytes, we're create a segments which are composition of peer ID and sequential number:
#[derive(Clone, Copy, PartialEq, Eq, Ord, PartialOrd, Hash, Default)]
struct Segment {
peer: PeerId,
seq_no: u32,
}
We also slightly modify the standard algorithm with following rule: when adding a new segment for fractional index, we first check if current left segment was created by the same peer. If so, we'll try to just bump up the sequence number. Otherwise we copy left segment and iterate deeper in order to generate next segment (until we'll be able to introduce one with current peer as an owner).
#[derive(Clone, PartialEq, Eq, Ord, PartialOrd, Hash)]
pub struct NonInterleavingIndex(Vec<Segment>);
impl FractionalIndex for NonInterleavingIndex {
fn new(peer_id: PeerId, left: Option<&Self>, right: Option<&Self>) -> Self {
let min = &[Segment::new(peer_id, 0)];
let lo = left.map(|l| l.0.as_slice()).unwrap_or(min);
let hi = right.map(|r| r.0.as_slice()).unwrap_or(&[Segment::MAX]);
let mut sequence = Vec::new();
let mut i = 0;
let mut diffed = false;
while i < lo.len() && i < hi.len() {
let l = lo[i];
let r = hi[i];
let n = Segment::new(l.peer, l.seq_no + 1);
if r > n {
if n.peer != peer_id {
// segment peers differ, copy left and
// descent to next loop iteration
sequence.push(l);
} else {
sequence.push(n);
diffed = true;
break;
}
} else {
sequence.push(l);
}
i += 1;
}
let min = Segment::new(peer_id, 0);
while !diffed {
let l = lo.get(i).unwrap_or(&min);
let r = hi.get(i).unwrap_or(&Segment::MAX);
let n = Segment::new(peer_id, l.seq_no + 1);
if r > &n {
sequence.push(n);
diffed = true;
} else {
sequence.push(*l);
}
i += 1;
}
Self(sequence)
}
}
How will it work in our interleaving example above?
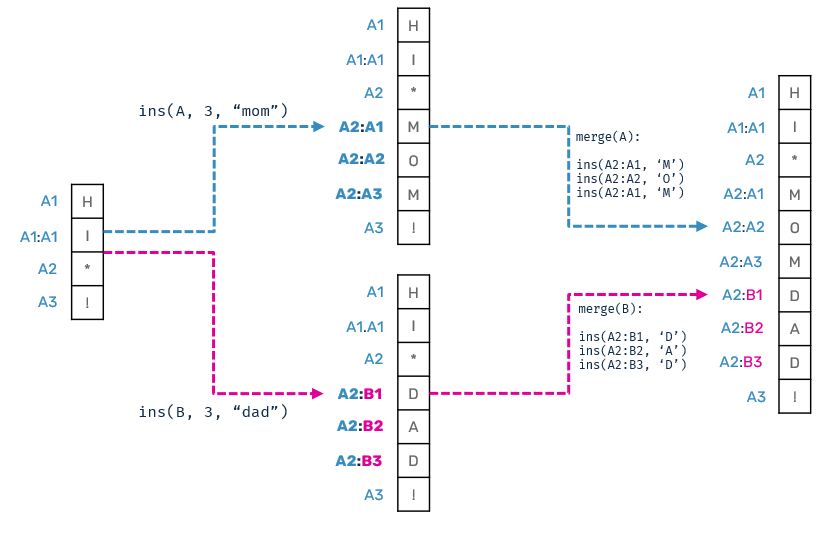
You may also noticed that we don't append peer ID at the end of the sequence - we don't need to since every individual segment now contains the peer info.
The disadvantage of that approach is that while we originally produced fractional indexes of size = n + sizeof(peer_id), here it becomes n * (4 + sizeof(peer_id)).
Naturally LSeq fractional indexes are subjects to some pathological behaviours i.e. when two peers start editing at the same cursor position and continue to do so even when synchronization happens in near-realtime. In such case the depth of fractional index sequence grows very fast - as we're continuously insert new elements in-between directly adjacent neighbours. Such behaviour will be even more visible in this implementation (since we append next segment every time when left neighbour was not created by the same user). It's up to you if you consider this a real issue of an acceptable trade off.
PS: Thanks to Twitter I was pointed to another implementation of this algorithm in TypeScript, made by Matthew Weidner.
Comments