Last time we were discussing how to build a Commutative Replicated Data Types operating as indexed sequences - preserving order of inserted elements - using two different data structures: Linear Sequences (LSeq) and Replicated Growable Arrays (RGA).
In this blog post we'll continue the topic and describe some possible modifications to original RGA algorithm - known as Block-wise Replicated Growable Array - that will let it fit better into scenarios, where we insert and delete entire ranges of elements.
Other blog posts from this series:
- An introduction to state-based CRDTs
- Optimizing state-based CRDTs (part 1)
- Optimizing state-based CRDTs (part 2)
- State-based CRDTs: Bounded Counter
- State-based CRDTs: Maps
- Operation-based CRDTs: protocol
- Operation-based CRDTs: registers and sets
- Operation-based CRDTs: arrays (part 1)
- Operation-based CRDTs: arrays (part 2)
- Operation-based CRDTs: JSON document
- Pure operation-based CRDTs
- CRDT optimizations
A prerequisite here is for you to understand how RGA works: how to insert elements after predecessor, resolve conflict of concurrent inserts at the same position or tombstone removed elements. If you're not comfortable with this data type, please read a previous blog post first.
As usually, here we'll support ourselves with most crucial snippets of the code, which full version can be found here.
Why do we even care?
One of the common use cases for indexed CRDT sequences is collaborative text editing. We already mentioned it - we'd like to be able to operate over a piece of document in peer-to-peer fashion (no central server), also offline if necessary. Algorithms presented in this blog so far would fit great to this purpose, but... there's a problem of scale.
Editing piece of text by multiple users means sending very small pieces of data (characters) with high frequency and volume. In traditional CRDTs this comes with two issues: a fairly high metadata overhead applied on each character and the cost of insertion of multiple adjacent elements. Metadata size can be amortized when stored on disk. What about in-memory size and computational cost?
Let's use an example: imagine that we're about to copy-paste huge piece of text into our collaborative text editor eg. few pages consisting of possibly thousands of characters. Using the approach we discussed so far this would be converted into thousands of separate insert operations, each with its own metadata.
Question is: couldn't we just insert a block of text as a single element? In theory, yes. In practice this would mean that with existing approach our block of text would become one immutable piece of data, that cannot be split (forget about inserting text in between pasted characters).
Below we're going to describe algorithm for insertion and deletion of multiple elements at once.
Block-wise Replicated Growable Arrays
One of the core principles for indexed CRDTs was sticking a unique ID to every inserted element, that will can be used to track it for the end of times. This seems to cause an impossible to solve problem: each block ID must be unique and persistent to that block. Otherwise when a concurrent update arrives from remote peer we may no longer be able to tell to which position in current, locally-modified RGA it was referring to. For that we need to refer to absolute unique IDs. On the other side when we want to insert another block in the middle of existing one, it needs to be split in two - and each of these needs unique ID.
In the solution below, we'll identify each block by the virtual pointer (unique identifier assigned when block was inserted) together with initial offset from the beginning of inserted block.
type VPtr = (int * ReplicaId)
type VPtrOff = { Ptr: VPtr; Offset: int }
type Content<'a> =
| Content of 'a[]
| Tombstone of int // number of consecutive tombstoned items
type Block<'a> = { Ptr: VPtrOff; Data: Content<'a> }
type Rga<'a> = { Sequencer: VPtr; Blocks: Block<'a>[] }
When a new block is inserted, its offset is always 0. When we need to split it, we produce two blocks (left and right side of a split), both of which have the same virtual pointer, but with different offsets, where right one's is shifted by the length of the left one. This process can be imagined as:
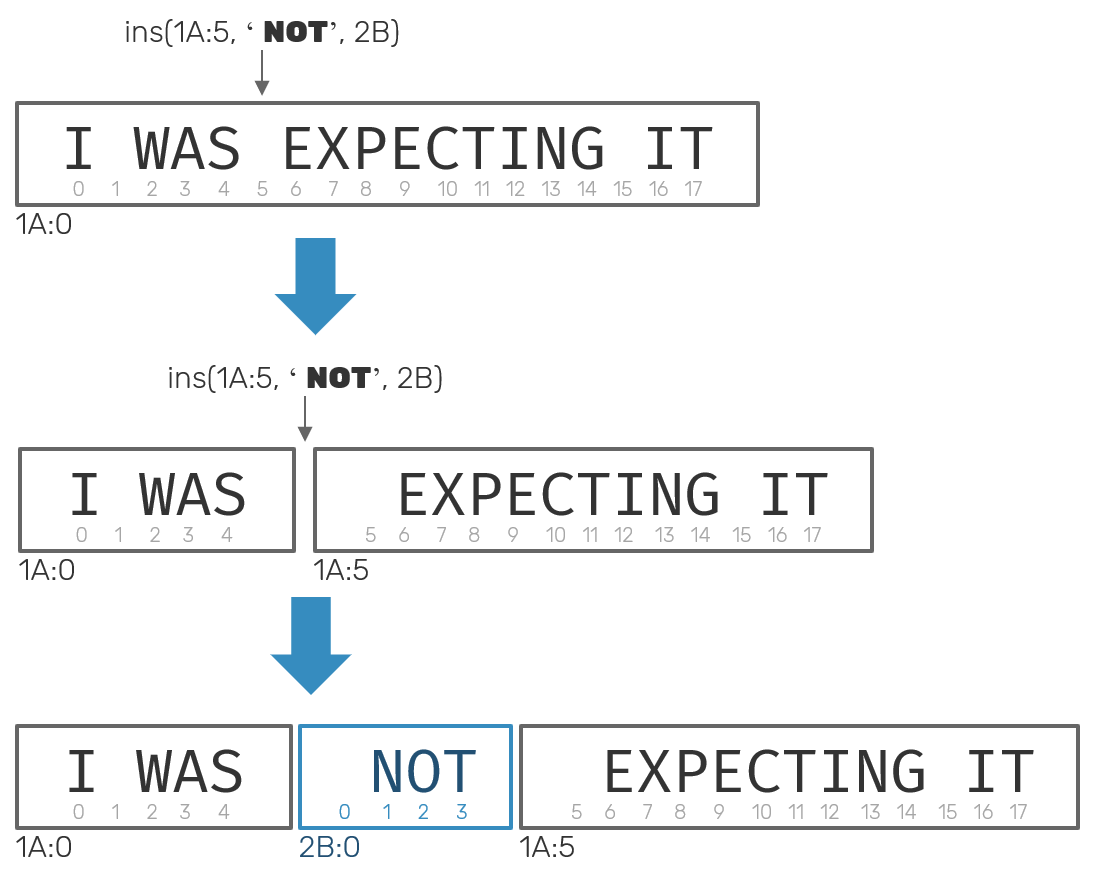
Knowing that, we can represent splitting in following form:
module Block
let split index (block: Block<'a>) =
// check if it's possible to slice the block
if index = block.Length then (block, None)
else
let ptr = block.PtrOffset
let (a, b) = block.Data.Slice index // slice the data in two
let left = { block with Data = a } // re-assign left slice to left block
let rightPtr = { ptr with Offset = ptr.Offset + index }
let right = { PtrOffset = rightPtr; Data = b }
(left, Some right)
The next piece of our insertion algorithm is an ability to determine where the split index should be located. We already discussed how to map user-facing index into actual RGA position with regards to tombstones, but now we have to go deeper - we'll need not only position of the block but also index position within the block itself:
let findByPositionOffset (p: VPtrOff) blocks =
let rec loop idx p (blocks: Block<'a>[]) =
let block = blocks.[idx]
if block.PtrOffset.Ptr = p.Ptr then
if block |> Block.containsOffset p.Offset
then
// we found the correct block, now we need an index within that block
let blockIdx = p.Offset - block.PtrOffset.Offset
(idx, blockIdx)
else loop (idx+1) p blocks
else loop (idx+1) p blocks
loop 0 p blocks
With all of these at hand insertion is similar to plain old RGA algorithm:
- Find predecessor after which we need to insert our element.
- If insert should be done inside of the predecessor block, split it in two.
- If another block was inserted concurrently resolve the insertion index of the new block based on virtual pointer ordering (as we covered in previous blog post).
- If split occurred in pt.2, replace predecessor block with its left half and insert the right one just after newly inserted block.
let applyInserted predecessor ptr items rga =
let (index, blockIndex) = findByPositionOffset predecessor rga.Blocks
// in case of concurrent insert of two or more blocks we need to check which of them
// should be shifted to the right and which should stay, and adjust insertion index
let indexAdjusted = shift (index+1) ptr rga.Blocks
let block = rga.Blocks.[index]
// since we're about to insert a new block, its offset will always start at 0
// (it can only be changed, when the block is subject to slicing)
let newBlock = { PtrOffset = { Ptr = ptr; Offset = 0}; Data = Content items }
let (left, right) = Block.split blockIndex block
let blocks =
rga.Blocks
|> Array.replace index left // replace predecessor block if split occurred
|> Array.insert indexAdjusted newBlock // insert new block
// if split occurred we also need to insert right block piece back into an array
let blocks = right |> Option.fold (fun blocks b -> Array.insert (indexAdjusted+1) b blocks) blocks
// update sequencer
let (seqNr, replicaId) = rga.Sequencer
let nextSeqNr = (max (fst ptr) seqNr, replicaId)
{ Sequencer = nextSeqNr; Blocks = blocks }
Range deletion
Deleting a range of elements is much more mind-boggling exercise. From the user perspective it should look simple: we pick start index and remove a continuous number of elements out of it. The problem is that this sequence of removed elements may be spanned over multiple RGA blocks, possibly starting and/or ending in the middle of one.
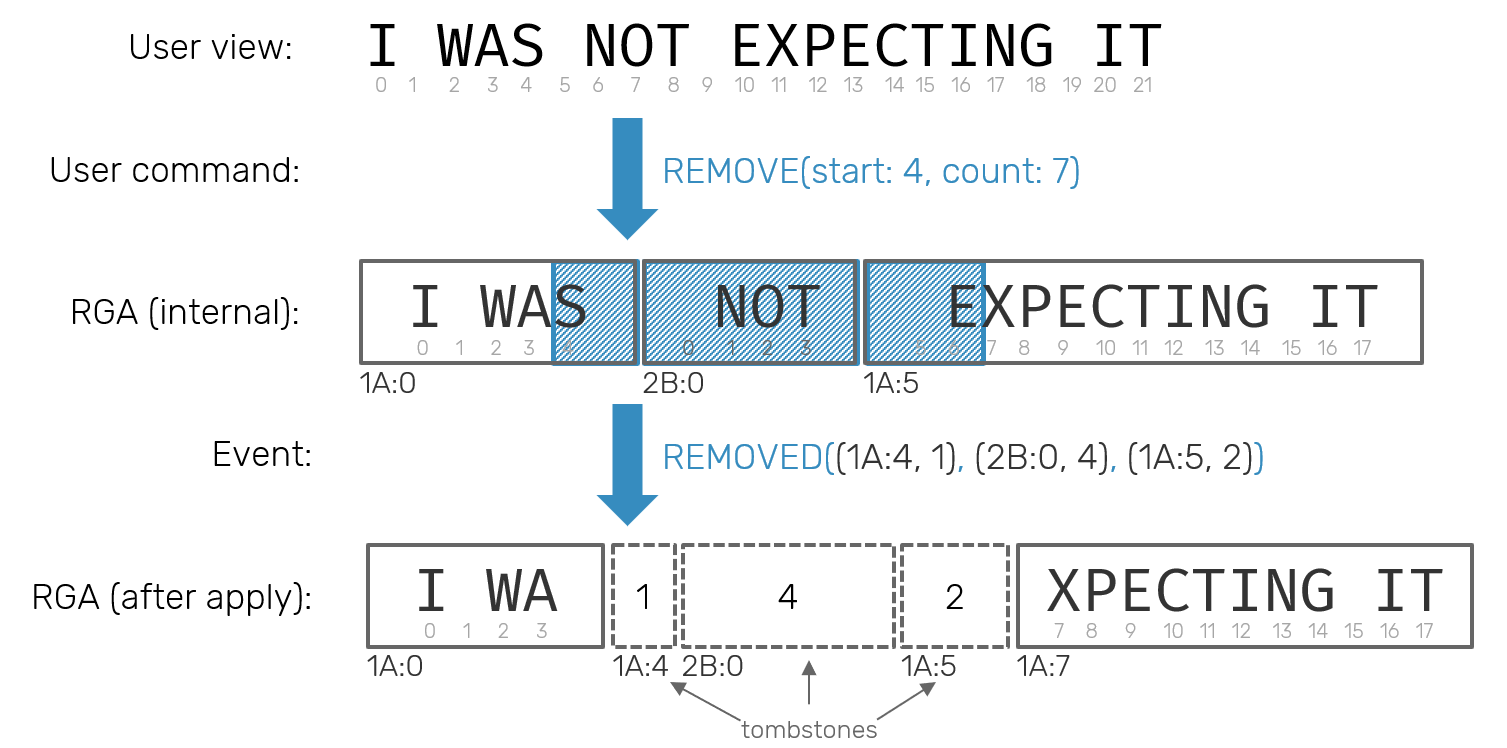
The distinction between command (user request) and event (replicated operation) is that events must not relate to user-facing indexes - as they are mutable and therefore not trustworthy when doing concurrent updates - but use block's virtual pointers with offsets + number of tombstoned elements - that number only really matters for the first and last block, as we can trust that all blocks in between will be deleted entirely (as they can only be splitted, but never joined).
type Command<'a> =
| Insert of index:int * 'a[]
| RemoveAt of index:int * count:int
type Operation<'a> =
| Inserted of predecessor:VPtrOffset * ptr:VPtr * value:'a[]
| Removed of slices:(VPtrOffset*int) list
Block splitting operation may come handy once again, when a removal range starts or ends in the middle of the block - as you've seen, the only two valid states for each block are either tombstoned or alive (having active elements). Nothing in between. In that case we can always split that block and tombstone a part, that needs to be removed.
Things we also need to think about are:
- What if blocks that are subject to tombstoning, were split in the meantime by another, concurrent operation? We still need to find and tombstone them given their old shape at the time when event was originally produced.
- What if concurrent operation inserted new block in the middle of deleted range? Since it was not part of deleted range it should be displayed, we cannot tombstone it by accident or we'd end up with corrupted state.
These and many more questions are not necessarily very easy to express in code. For our implementation we simply assume that list of slices provided with Removed event is ordered adequately to their order in RGA itself: it has sense, as blocks can be inserted or split, but never reordered meaning that we never run into situation where RGA with blocks [A,B,C] will be transformed into [B,A,C].
The core skeleton of removal algorithm looks like this:
let applyRemoved slices blocks =
let rec loop (acc: ResizeArray<Block<'a>>) idx slices (blocks: Block<'a>[]) =
match slices with
| [] ->
// once we tombstoned all expected blocks, just copy over remaining ones
for i=idx to blocks.Length-1 do
acc.Add blocks.[i]
acc.ToArray()
| (ptr, length)::tail ->
let block = blocks.[idx]
if block.PtrOffset.Ptr = ptr.Ptr then // we found a valid block
// block tombstoning algorithm body...
else
// this is not a block we're looking for, just copy it over as is
acc.Add block
loop acc (idx+1) slices blocks
loop (ResizeArray()) 1 slices blocks // start from 1 as 0 is RGA head element
We omitted a body of tombstoning algorithm for a moment to think about possible scenarios. We could put them into following categories:
- Removal start position is inside of a given block.
- Removal start position is outside of a given block - which is possible eg. because another concurrent operation had already fragmented it into more blocks.
We can represent these as:
// block tombstoning algorithm body...
if block |> Block.containsOffset ptr.Offset then
// the tombstoned slice starts inside of a current block...
else
// position ID is correct but offset doesn't fit, we need to move on
acc.Add block
loop acc (idx+1) slices blocks
Again we left one branch untouched - we know that we found the block we want to tombstone, but we first need to determine if the removed range starts at with the beginning of that block or somewhere in the middle:
let splitIndex = ptr.Offset - block.PtrOffset.Offset
let tombstone : Block<'a> =
if splitIndex = 0
then block // beginning of tombstoned block is exactly at the beginning of current one
else
// beginning of tombstoned block is in the middle of current one
// split it in two and keep the left part alive
let (left, Some right) = Block.split splitIndex block
acc.Add left
right
// tombstone...
So, this way we handled the left boundary of our removal range. Now to the right one - we need to check if number of removed elements matches the number of elements of the block itself:
- Usually a number of removed elements will fit within the bounds of the current block. We may again run into situation, when we need to split that block in two, tombstone the left part and keep around the right one.
- If concurrent update caused tombstoned block to be split if may turn out that the number of elements we're about to remove, is longer than the current block. In that case we need to tombstone the entire block and reinsert the updated slice (shortened by the number of elements we just tombstoned) back to the list of slices used to idenitify blocks to be removed.
// tombstone...
if length <= tombstone.Length then
// split the block if number of elements to be removed is not equal its length
let (left, right) = Block.split length tombstone
acc.Add (Block.tombstone left) // tombstone left part
right |> Option.iter acc.Add // if right part exists, add it to the result RGA
loop acc (idx+1) tail blocks
else
// tombstone length is longer than size of a block
acc.Add (Block.tombstone tombstone)
// update slice to contain remaining length to be tombstoned
let remaining =
/// take a slice and shorten it by moving its pointer offset
/// and reducing to-be-removed length
let ptr = { ptr with Offset = ptr.Offset + tombstone.Length }
let remainingLength = length - tombstone.Length
(ptr, remainingLength)
// put remaining part back onto processing list
loop acc (idx+1) (remaining::tail) blocks
Uff, that's a lot of code for a single function, but we got a lot of cases to cover. If you're confused, feel free to help yourself with the source.
Summary
We described how to build a variant of Replicated Growable Array from the previous post, optimized for insertion and deletion of entire ranges of elements at the same time.
In this implementation we used an ordinary arrays, which were copied to maintain immutable characteristics. You probably already know, that this is not the most efficient approach. In practice structures like ropes are much better suited for this sort of workload.
You may have noticed that block slicing may eventually lead to suboptimal situation, where our entire sequence is internally fragmented into single character blocks, causing it to be more expensive than original RGA structure. For some situations this may be a valid concern. However for cases like collaborative text editing, which was the major motivation for this algorithm the cons shouldn't overwhelm the pros in most of the practical scenarios.
Comments