Today we'll continue a series about CRDTs, this time however we'll stray from the path of state-based CRDTs and start talking about their operation-based relatives. The major difference that we need to cover, is the center of gravity of this approach: the replication protocol.
Other blog posts from this series:
- An introduction to state-based CRDTs
- Optimizing state-based CRDTs (part 1)
- Optimizing state-based CRDTs (part 2)
- State-based CRDTs: Bounded Counter
- State-based CRDTs: Maps
- Operation-based CRDTs: protocol
- Operation-based CRDTs: registers and sets
- Operation-based CRDTs: arrays (part 1)
- Operation-based CRDTs: arrays (part 2)
- Operation-based CRDTs: JSON document
- Pure operation-based CRDTs
- CRDT optimizations
While we've rarely even mentioned it in case of Convergent Replicated Data Types. Thanks to associativity, commutativity and idempotency powering the merge operator, replication was not really an issue. Here it's the main difficulty. It has its merits though - once we're done with it, our path will be paved into much simpler and more straightforward data type implementations.
In this blog post we'll cover necessary properties to be satisfied by such protocol, discuss technical challenges of its practical implementation and at the end provide a first most basic op-based CRDT.
Prerequisites
Since CRDTs have been discussed on this blog many times, we're not going to cover everything from scratch. You should understand motivation behind them - what they are, where and why we're using them for. If you're not familiar with it, please read this introduction.
Another piece, we're not going to discuss in detail (because we already did) are vector clocks, which will be used in further implementation.
While it's not strictly necessary knowledge, it will be useful for you to know the basic concepts of eventsourcing, as we're going to refer to them by analogy later on.
For the implementation part of this blog post, we're going to use F# and Akka.NET. We do so, because we need a thread-safe state modification in face of concurrent updates, and actor programming model is pretty good way to achieve that.
Protocol
The core replication protocol used for operation-based CRDTs can be described as Reliable Causal Broadcast (RCB), which is not really a name of some algorithm but rather a set of requirements that this protocol must satisfy. Let's go and define what does it mean.
Reliability
In this context reliable means: all updates visible locally must be eventually seen by others, always. Sounds trivial, right? Just put TCP pipe between two nodes and we're done Nope. Sometimes, we can get periodic disconnects, while the system should keep on going. Even more: we may have updated state locally, our system was shutdown and came back up. If we committed them locally, we still need to send these updates to other peers. Otherwise we end up in desynchronized state.
More importantly, CRDTs are known by their instantaneous response time for updates. We shouldn't have to wait for others to confirm receiving the update before confirming it locally. CRDTs are meant to work independently (including offline mode) and we want to maintain that property.
Now, there's a known way of persisting operations known as eventsourcing, which as you'll see, plays nicely with the rest of our requirements. We'll persist our updates as events and replay them on demand. Now we only need to figure out how to replicate them to others...
Causality
We could ask ourselves: maybe we just let Kafka/Pulsar/event-log-of-the-week carry this problem for us? But we (indirectly) already answered it: we need our nodes to operate independently. Most of the existing distributed event logs replicate events by establishing consensus about the total order of events they all share within the scope of a given topic. This means that they need to coordinate that order with each other. Therefore when working within a group (cluster), they cannot establish the order of events on their own. Neither can they work when in offline mode.
This is where causality aka. happens-before relation comes in. As it turns out it's not possible to have one total order of replicated events AND let nodes to write events independently at the same time. We cannot eat cake and have it too. The max we can offer is partial order in form of causal ordering. What does it mean?:
-
We CAN guarantee the order of events within the scope of a single node/actor. Eg. If Alice wrote letters A then B, everyone reading her messages will always see A happening before B.
-
We CANNOT guarantee order of concurrent updates. Eg: if Alice wrote A and Ben wrote B at the same time (before they replicated each other's events), after replicating their changes to others, some peers may see events in order A→B, while others B→A. It's a necessary tradeoff of working independently.
-
We CAN guarantee order of events, when one of them could cause (hence name causal) another one to happen, even if they happened on different nodes. Eg:
- Alice wrote A, which was replicated to Ben and Sam.
- After receiving A, Ben replied with B. Sam responded to A with C "in the same time" (meaning C and B were not yet replicated between the nodes).
Now, after replicating all events, what's will be a possible order? We could see A→B→C or A→C→B (because of point 2), but we can promise that B and C will NEVER be visible before A (like in point 1). This means that we will never see an answer before question it refers to.
If we were thinking about usual order of events as a single linear timeline, we could visualize partial order as something that resembles more a tree-like structure - think for example about git repo, where every concurrent update is a new branch and replication leads to branch merges.
To establish total order, a popular technique is to use timestamps (in form of date or some sequence numbers). But it's not enough for partial order, as such timestamp alone doesn't cover enough information to recognize events that happened concurrently. We'll use vector clocks for that.
Now, let's reimagine scenario from point 3:
- Alice is sending event A.
- A was replicated to Ben, but not to the Sam eg. because they got disconnected.
- After receiving A, Ben produced event B.
- Sam still can talk with Ben, so the replication works between these two. Now we need to ensure, that Sam won't observe B before A (which was produced by Alice).
We can imagine this case in form of a chat talk like one seen below:
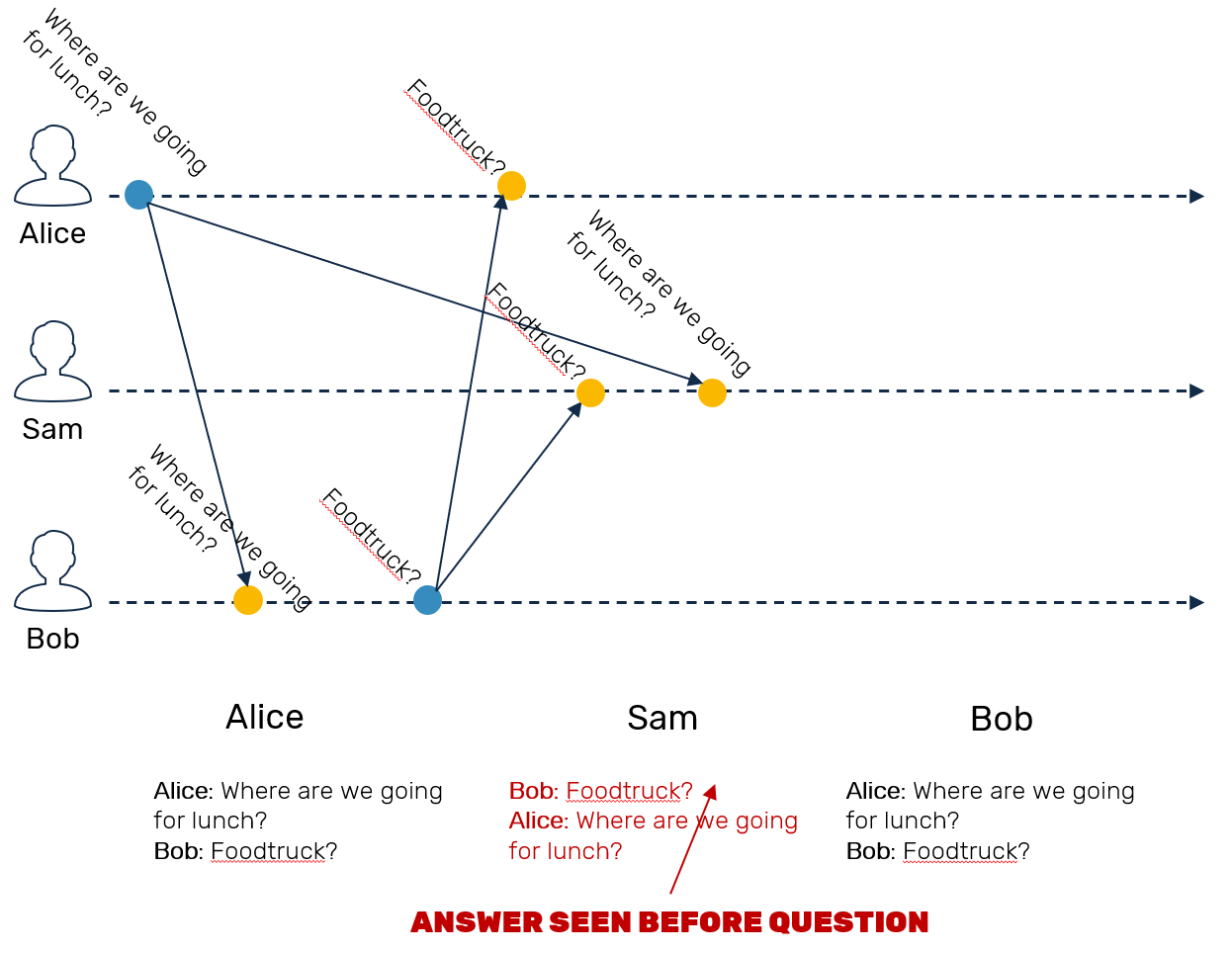
Replication
As you can see, naive push notifications won't work here. If Ben would only send his own events to Sam, he would receive incomplete history of known preceding events. Now, there are two popular ways of dealing with this issue.
Hiding non-continuous segments of the event stream
Each peer replicates by pushing its events, but the receiver keep tracks of the holes (eg. if we received events with timestamps {A:1,B:1} and {A:2,B:3} we can infer that there was some event with B:2 in between, which we missed). Now we mark all events that happened after missing event as invisible until it arrives.
This can be problematic eg. when one peer went offline for long time before sending event to everyone else - in that case peers which didn't receive it, will have to keep invisible (and growing) backlog of events, possibly forever.
Allowing replication of other peer's events
Another way is to let peers replicate not only events produced by themselves, but also events emitted by other peers. Using example from above, while Sam is unable to receive event A from Alice (cause they are disconnected) he still can receive it together with B from Ben. This way be can prevent "holes" in event stream timeline from happening.
Now this means, that we need to deal with duplicates - a lot of duplicates. Given N peers, each one sending events of all others, we get (N-1)^2 messages flying over the network. How can we improve that? Let's try to reverse the direction: first, instead of sender pushing the notifications to all receivers, we'll make each receiver pull events from the sender.
Pull-based model alone is not enough to fix the issue with sending duplicates though. This is why we'll add one more thing: when sending pull request, we'll send a timestamp describing all events, which pulling peer observed so far. This way we'll give sender a hint about which events on its stream could be skipped (because we've already seen them). Since this alone is still not guarantee for avoiding duplicates - as replication with multiple peers usually happens concurrently - receiver still needs to detect and skip potential duplicates on its own side as well.
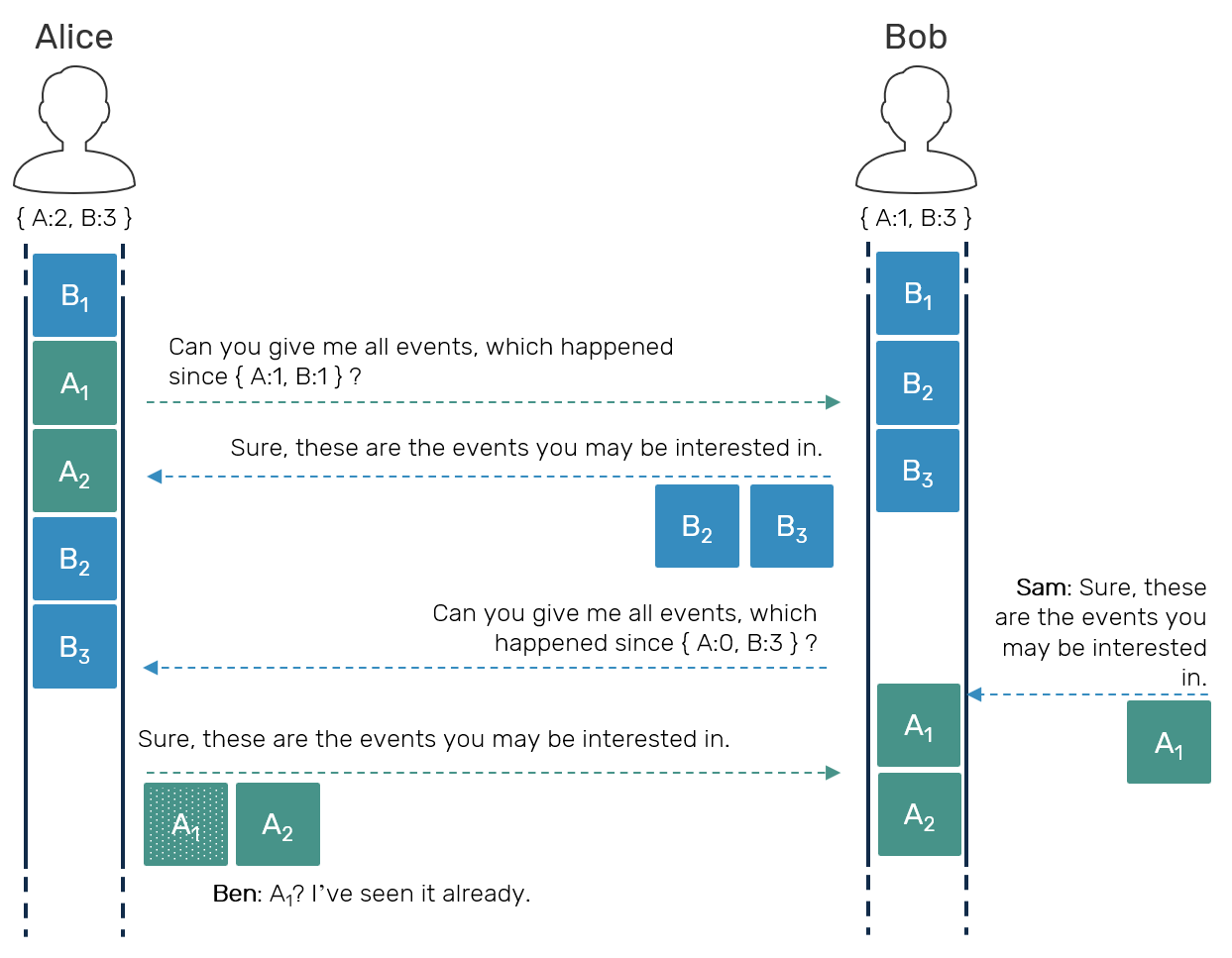
So, while we didn't fully removed the issue, we amortized it to be much less of a problem.
Implementation
We're going into deep dive o a sample implementation, however we're not going to cover all required code here. Please use this snippet if you're get lost.
As usual, when it comes to an actual implementation, things are getting complicated. Example: We were talking about replicating events by having a destination pull first with its vector clock to let the receiver filter events out on its side. Sounds easy? So how are we actually going to do so? Are we going to go through entire event stream from the very beginning, read each one and determine if its should be replicated or not? This request will be repeated frequently, while the stream itself could have possibly millions of events.
Most of the eventsourcing systems order their events using sequence numbers. It's simple - we keep a persisted counter, that we're going to increment each time, we're about to store a new event. While we can indeed use this idea here, there's one catch: we cannot have one counter shared by all replicas. This would require coordination between replicas, which was one of the things we wanted to avoid, for the reasons mentioned above.
Because of that we're going to:
- Let each replica keep it's own unique counter to producing sequence numbers.
- Store a separate map, that will keep track of the sequence numbers we've replicated from others so far.
This way, when sending a replication request, we could simply say: please give me all events that starts from your sequence number X that are greater or concurrent with a my vector clock Y. With this at hand we can represent our events as:
type Event<'e> =
{ Origin: ReplicaId
OriginSeqNr: uint64
LocalSeqNr: uint64
Version: VTime
Data: 'e }
while our replica state could look like this:
type ReplicationState<'s> =
{ Id: ReplicaId // unique ID of replica
SeqNr: uint64 // counter used to assign local sequence numbers
Version: VTime // the highest timestamp observed so far
Observed: Map<ReplicaId, uint64> // remote sequence numbers per replica
Crdt: 's } // actual state of our CRDT
As you may remember we wanted to know when another replica has seen the state. We can do so by comparing last sequence number of observed replica we got so far and the currently observed vector clock of both incoming event and our own replication state:
[<RequireQualifiedAccess>]
module ReplicationState =
/// Checks if current event has NOT been observed by a replica identified by state
let unseen (state: ReplicationState<'s>) (e: Event<'e>) =
match Map.tryFind e.Origin state.Observed with
| Some ver when e.OriginSeqNr > ver -> true // event seqNr is higher than observed one
| _ ->
let cmp = Version.compare e.Version state.Version
cmp = Ord.Gt || cmp = Ord.Cc
CRDT API
In order to make this design work with CRDT in the generic manner, we're also going to need some abstraction to unify the necessary capabilities of our CRDTs. In literature these are quite well defined. Moreover, once you read through you'll see that operation-based CRDT's share many traits with eventsourced aggregate roots:
- We're going to need some way to obtain a default/empty/identity value of CRDT. It's quite understandable - as many peers may potentially start updating the same state without knowing or communicating with each other, there's no single point in time when we could "initialize" our object. For this reason we need to have some well-known default.
- We need to be able to query the state of a CRDT. Sometimes the CRDT itself consist not only of the actual state, user is interested about, but also some metadata used for conflict resolution. This was extremely common in state-based CRDTs discussed in the past on this blog. Maybe we'll see how to split the metadata from the state completely in the future with so called pure operation-based CRDTs, but for this protocol we also have user-state and metadata combined from time to time.
- Another definition is a prepare method, which is almost identical to a command handler from eventsourcing methodology. We basically take some operation send by the user, and change it into event (potentially enriched with CRDT metadata).
- The last method is an effect (this time analogous to event handler), which will be applied upon our CRDTs whenever event - either created locally or replicated from remote replicas - arrives.
All of these would be great example to create beautiful hierarchy of higher kinded types, however since we don't have these in F#, an ordinary interfaces must suffice:
[<Interface>]
type Crdt<'crdt,'state,'cmd,'event> =
abstract Default: 'crdt
abstract Query: 'crdt -> 'state
abstract Prepare: state:'crdt * command:'cmd -> 'event
abstract Effect: state:'crdt * event:Event<'event> -> 'crdt
Store
We're also going to need a store itself. Here, our requirements are not really very constraining:
[<Interface>]
type Db =
/// Persist provided state snapshot.
abstract SaveSnapshot: state:'s -> Async<unit>
/// Load the latest known state snapshot if there's any.
abstract LoadSnapshot: unit -> Async<'s option>
/// Load ordered events with sequence number,
/// that's equal or greater than provided one.
abstract LoadEvents: startSeqNr:uint64 -> AsyncSeq<Event<'e>>
/// Persist events, maintaining their sequence number ordering.
abstract SaveEvents: events:Event<'e> seq -> Async<unit>
As you may imply from this declaration, we won't cover data deletion nor serialization, as these are outside the scope of this blog post.
You may notice, as we originally mentioned, that we're going to filter replicated events by vector clock, yet none is provided here. The reason for that is simple: so far I didn't found a database engine, that's able to natively understand the concept of version clocks and take advantage of them. We need to do that on application level. For this reason we also track ordering by sequence number, as this concept is well understood by most databases.
Local state recovery
Here, a replicator is our actor responsible for managing the state of our CRDT, its event stream and process of replicating event log with other replicators.
Before replicator will be able to serve any incoming requests, first it must recover its state from a persistent store. This can work pretty much like a standard eventsourced state recovery: we first try to read the latest snapshot and then replay all of the events that have happened since the snapshot was made. Local sequence number can be used to order snapshots and events in linear sequence.
We start by trying to load a last saved snapshot of the state, if such existed - otherwise we'll use the default instance of our CRDT. Next we're going to iterate over all locally persisted events that happened since that snapshot - this implies that state itself contains a corresponding sequence number at the time it was made - and apply them to our state.
async {
// load state from DB snapshot or create a new empty one
let! snapshot = db.LoadSnapshot()
let mutable state =
snapshot |> Option.defaultValue (ReplicationState.create id crdt.Default)
// apply all events that happened since snapshot has been made
for event in db.LoadEvents (state.SeqNr + 1UL) do
state <- { state with
Crdt = crdt.Effect(state.Crdt, event)
SeqNr = max state.SeqNr event.LocalSeqNr
Version = Version.merge event.Version state.Version
Observed = Map.add event.Origin event.OriginSeqNr state.Observed }
ctx.Self <! Loaded state
} |> Async.Start
recovering db ctx
All of that is pretty standard way of recovering state of aggregates in eventsourced systems. However as you may see in the snippet above our state consists of more than just simple user-defined data:
Crdtis the actual replicated data type with user info, that we care about, sometimes enriched with CRDT-specific metadata. This piece is specialized depending on what CRDT our replicator is responsible for.LocalSeqNris the sequence number in a current replica. It's going to be incremented with every persisted event - no matter if it was replicated from remote replica or created locally.Versionis a vector version that describes the most recent timestamp. We're also going to increment its segment (responsible for current replica), but only for events created locally.Observedis a map that describes pairs ofreplicaId→originSeqNrof all known replicas. We use it, so that when we're about to start/resume replication with other remote replicas, as continuation point in their event log.
You might ask: if both Version and Observed fields can be represented as Map<ReplicaId, uint64>, so how do they differ? Version counters are incremented ONLY when related replica is an origin (original creator) of an event, and only when a new event was created, not replicated. Observed map tracks sequence numbers. Each event log increments it's own sequence number every time it persist an event - it doesn't matter if that event was created locally or replicated from remote node. Observed map keeps track, up to which sequence number (relative to each replica) is current node synchronized.
Changing request into events
In eventsourcing, we have two types of messages. We already covered events - persisted, immutable and undeniable facts describing what already happened. Another kind are commands - these are user-made requests, that should result in a production of event: user-defined state should only change in result of events, not commands.
Of course, since our state parameter contains also some metadata - like SeqNr and Version which should be incremented prior to generation of new event - we need to update at least system-specific part of that state.
let replicator crdt db id (ctx: Actor<Protocol<_,_,_>>) =
let rec active db state replicatingNodes = actor {
match! ctx.Receive() with
| Command(cmd) ->
let requester = ctx.Sender()
let seqNr = state.SeqNr + 1UL
let version = Version.inc state.Id state.Version
// generate user-event as result of a command
let data = crdt.Prepare(state.Crdt, cmd)
let event = { Origin = state.Id; OriginSeqNr = seqNr; LocalSeqNr = seqNr; Version = version; Data = data }
do! db.SaveEvents [event]
// apply event to a state
let ncrdt = crdt.Effect(state.Crdt, event)
let nstate = { state with Version = version; SeqNr = seqNr; Crdt = ncrdt }
requester <! crdt.Query ncrdt
return! active db { nstate with IsDirty = true } replicatingNodes ctx
// ... other cases
}
After whole operation succeeded - just for convenience - we're going to send to requester a new, modified state view.
Now, we should discuss how to replay/sync events coming from a remote event log.
Remote replica synchronization
While we replayed local state via AsyncSeq - which C# programmers may know better as IAsyncEnumerable and others as streams - for remote event replication we'll use different approach. Replicating events one by one - either be it from local file storage or over the network - is not the best option, especially when events themselves are quite small. We need to pay extra toll for every network request made. Much better approach is to do it in batches.
We start by connecting one replica to another:
let replicator crdt db id (ctx: Actor<Protocol<_,_,_>>) =
let rec active db state replicatingNodes = actor {
match! ctx.Receive() with
| Connect(nodeId, endpoint) ->
let seqNr = Map.tryFind nodeId state.Observed |> Option.defaultValue 0UL
endpoint <! Replicate(seqNr+1UL, 100, state.Version, ctx.Self)
let timeout = ctx.Schedule recoverTimeout ctx.Self (RecoverTimeout nodeId)
return! active db state (Map.add nodeId { Endpoint = endpoint; Timeout = timeout } replicatingNodes) ctx
// ... other cases
}
Given the replica node identifier and its access endpoint, we can check what was the most recent sequence number of that replica's event log, we've seen so far: this is why Observed property exists in our replica state. Then we can use it - together with vector version describing our observed timeline. We do so to avoid problem of replicating N^2 events, as mentioned above. Finally we want to keep track of the nodes we called - for this reason we use replicatingNodes parameter. The reason why we have separate state.Observed and replicatedNodes is that first one is persisted, while later represents transient state (like timers).
Now, what happens when remote replica receives Replicate request?:
let replay nodeId (filter: VTime) target seqNr count = async {
use cursor = db.LoadEvents(seqNr).GetEnumerator()
let buf = ResizeArray()
let mutable cont = count > 0
let mutable i = 0
let mutable lastSeqNr = 0UL
while cont do
match! cursor.MoveNext() with
| Some e ->
if Version.compare e.Version filter > Ord.Eq then
buf.Add(e)
i <- i + 1
cont <- i < count
lastSeqNr <- Math.Max(lastSeqNr, e.LocalSeqNr)
| _ -> cont <- false
let events = buf.ToArray()
target <! Replicated(nodeId, lastSeqNr, events)
}
Just like in case of local state recovery, we're going to iterate through events, starting from a given sequence number. However, we're going to batch these elements up to specified capacity. We're also not including events, which Version was less or equal to the version vector of a remote replica.
Additionally we also want to remember and return the last visited sequence number. Why don't just infer it straight from passed events? It's possible that every event present in current event log was already seen by our caller (its vector version doesn't pass the filter), therefore making batch empty. In that case we want to give it last visited sequence number anyway, simply so that when the next Replicate request arrives in the near future, we won't iterate over all of these already observed events again.
let replicator crdt db id (ctx: Actor<Protocol<_,_,_>>) =
let rec active db state replicatingNodes = actor {
match! ctx.Receive() with
| Replicated(nodeId, lastSeqNr, events) ->
let mutable nstate = state
let mutable remoteSeqNr = Map.tryFind nodeId nstate.Observed |> Option.defaultValue 0UL
let toSave = ResizeArray()
for e in events |> Array.filter (ReplicationState.unseen nodeId state) do
let seqNr = nstate.SeqNr + 1UL
let version = Version.merge nstate.Version e.Version
remoteSeqNr <- max remoteSeqNr e.LocalSeqNr
let nevent = { e with LocalSeqNr = seqNr }
nstate <- { nstate with
Crdt = crdt.Effect(nstate.Crdt, nevent)
SeqNr = seqNr
Version = version
Observed = Map.add nodeId remoteSeqNr nstate.Observed }
toSave.Add nevent
do! db.SaveEvents toSave
let target = Map.find nodeId replicatingNodes
target.Endpoint <! Replicate(lastSeqNr+1UL, 100, nstate.Version, ctx.Self)
let prog = refreshTimeouts nodeId replicatingNodes ctx
return! active db { nstate with IsDirty = true } prog ctx
// ... other cases
}
At this point we should already have some intuition about handling the Replicated event itself. Key points are:
LocalSeqNris relative to local replica sequence number. Therefore it must be replaced with incremented local sequencer value before persisting.- Don't blindly persist all of the incoming events, make sure they were not seen yet on the receiver side. Sure, we already filtered them once on the sender side, but since we can be replicating with many senders in parallel over unpredictable network, some duplicates are still possible.
Wrapping it all together
Again, feel free to use this gist with entire code, as not all of it is present in this blog post. We covered only (I hope) the most confusing parts. If you managed to keep up, congratulations! Our reliable causal broadcast replication protocol is ready. We're now prepared to start using it to build our first operation-based CRDTs :D
Since this article is already quite long, at the moment we'll only cover the most basic one - increment/decrement counter. We're going to follow to more advanced structures in upcoming blog posts.
[<RequireQualifiedAccess>]
module Counter =
let private crdt =
{ new Crdt<int64,int64,int64,int64> with
member _.Default = 0L
member _.Query crdt = crdt
member _.Prepare(_, op) = op
member _.Effect(counter, e) = counter + e.Data }
/// Create replication endpoint handling operation-based Counter protocol.
let props db replica ctx = replicator crdt db replica ctx
/// Add value (positive or negative) to a counter replica.
let add (value: int64) (replica) : Async<int64> = replica <? Command by
/// Get the current state of the counter from its replica.
let query (replica) : Async<int64> = replica <? Query
As you may see, the crdt instance here is extremely trivial. If you're disappointed you shouldn't. The reason why we've build so complex protocol was exactly to prepare a convenient platform for further work.
As you may see, unlike the state-based CRDT counter - which was backed by an underlying map(s) - this one is represented by one simple numeric value. Additionally command and event in this case are indistinguishable: we're going to keep them however for the future reference, as more advanced CRDTs may differentiate between the two.
References
- Eventuate is a JVM Akka plugin that offers replicated event logs and operation-based CRDTs, and it was main inspiration for this blog post.
- Slides from the presentation about leaderless peer-to-peer evensourcing I did a while ago. They brings more visual step-by-step explanations for some of the stuff we talked about here and hints for our future direction.
- AntidoteDB is another (Erlang) implementation of operation-based CRDTs, wrapped in a context of a geo-replicated database.
Comments