Last time we started our operation-based CRDTs sub-series, as we moved away from state-based CRDTs. We talked mostly about core requirements and sample implementation of RCB (Reliable Causal Broadcast) protocol, which was necessary to provide guarantees required by Commutative Replicated Data Types.
Today we'll continue the topic, as we're going to implement most common data types - registers and sets - in their operation-based variant.
Other blog posts from this series:
- An introduction to state-based CRDTs
- Optimizing state-based CRDTs (part 1)
- Optimizing state-based CRDTs (part 2)
- State-based CRDTs: Bounded Counter
- State-based CRDTs: Maps
- Operation-based CRDTs: protocol
- Operation-based CRDTs: registers and sets
- Operation-based CRDTs: arrays (part 1)
- Operation-based CRDTs: arrays (part 2)
- Operation-based CRDTs: JSON document
- Pure operation-based CRDTs
- CRDT optimizations
Before we begin...
We already defined the core abstractions of our data types to be implemented. You can get a quick recap of hows & whys under this link. Since this is a continuation, I highly encourage you to get familiar with previous blog post, as otherwise you may feel lost. Here we're only remind the crucial part - the Crdt interface definition, which gives a shared structure for our data types:
type Crdt<'crdt,'state,'cmd,'event> =
/// Initial CRDT instance.
abstract Default: 'crdt
/// Read CRDT value as user-friendly data type.
abstract Query: 'crdt -> 'state
/// Handle user request and produce a serializable event out of it.
abstract Prepare: state:'crdt * command:'cmd -> 'event
/// Handle event (either produced locally or replicated
/// from remote source) to modify the CRDT state.
abstract Effect: state:'crdt * event:Event<'event> -> 'crdt
You already could have seen an example Counter implementation in action. Now, let's go to more advanced structures.
Registers
Registers are one the most wide spread ways of working with CRDTs. The reason is simple: they allow us to wrap any sort of ordinary data types in order to give them CRDT-compliant semantics.
However, this comes at the price - we cannot simply change any non-CRDT value into CRDT without some compromises: if that would be possible, we wouldn't need CRDTs in the first place. For these, two popular approaches are known as last-write-wins and multi-value registers.
Last Write Wins Register
Last write wins is a popular way of dealing with conflicts being the result of concurrent updates in many systems (Cassandra is good example of a database that's quite known from this approach).
The algorithm - already mentioned in the past - is simple: on each register value update, we timestamp it. If our current timestamp is higher than the most recent one remembered by the register itself, we change the value, otherwise leave existing one (more recent) untouched.
What is our timestamp? The intuition says, that we could simply use current system clock (eg. DateTime.UtcNow in .NET API). However:
- We mentioned in the past that relying on a system clock to provide monotonically incrementing value can be naive assumption. While we're going to use it here for simplicity of implementation, I encourage you to look for other solutions (eg. Hybrid Logical Clocks).
- You never can be sure that reading a clock value concurrently on two different machines will always yield different results. While the risk is low, it's still possible to run into a situation when we have two different values sharing the same timestamp, exposing the integrity of our data in the result. For this reason we'll extend our timestamp to be a composite value: system clock + ID of the current replica. Since replica identifier is unique, it will ensure the same for our timestamp.
Given that we already prepared an API for building our CRDTs, this implementation is quite straightforward:
[<RequireQualifiedAccess>]
module LWWRegister
// this type is structuraly comparable: first compare dates,
// and if they're equal use replica ids
type Timestamp = (DateTime * ReplicaId)
type LWWRegister<'a> =
{ Timestamp: Timestamp
Value: 'a voption }
type Operation<'a> = DateTime * 'a voption
type Endpoint<'a> = Endpoint<LWWRegister<'a>, 'a voption, Operation<'a>>
let private crdt : Crdt<LWWRegister<'a>, 'a voption, 'a voption, Operation<'a>> =
{ new Crdt<_,_,_,_> with
// default register value - use lowest possible timestamp
// to make sure it will always loose with incoming update
member _.Default = { Timestamp = (DateTime.MinValue, ""); Value = ValueNone }
// return register value alone
member _.Query crdt = crdt.Value
// produce an event data to be persisted/replicated,
// timestamp it with clock only, as we get replica id
// from the wrapping Event type
member _.Prepare(_, value) = (DateTime.UtcNow, value)
member _.Effect(existing, e) =
// decompose our event data we created in Prepare method
let (at, value) = e.Data
let timestamp = (at, e.Origin) // create timestamp
if existing.Timestamp < timestamp then
// if given timestamp is more recent, return updated register
{ Timestamp = timestamp; Value = value }
else existing }
let props db replica ctx = replicator crdt db replica ctx
let updte (value: 'a voption) (ref: Endpoint<'a>) : Async<'a voption> = ref <? Command value
let query (ref: Endpoint<'a>) : Async<'a voption> = ref <? Query
One of the issues of last-write-wins approach is its inherent risk of data loss - we took an easy to use API at price of automatically throwing out potentially useful data.
Multi Value Register
Another approach is to build a register that doesn't drop any data, instead it keeps track of all causal (happened-before) relationships between updates and in case of conflicts returns all conflicting cases. It's known as Multi Value Register.
The common analogy we could use here to better understand this register's behavior would be a Git interactive merge resolution: when two people edit the same block of text and they git pull changes from each other, what we often see is information about unresolved merge conflicts. What can we expect then?:
- We're going to see not one, but both conflicting block updates, even when they relate to the same line of text.
- Once we resolve this merge conflict manually, we expect that all other people, who pulled our changes onward will be able to read value from our merge commit, so that they don't need to resolve the same conflicts again by themselves.
The same intuition applies to multi-value registers. We track causality of register updates, and in case of conflicts - as when two independent updates are happening concurrently - we'll provide all conflicting values. Programmer is then free to choose any value and override concurrent conflicts with more recent update. We can imagine that in the following scenario:
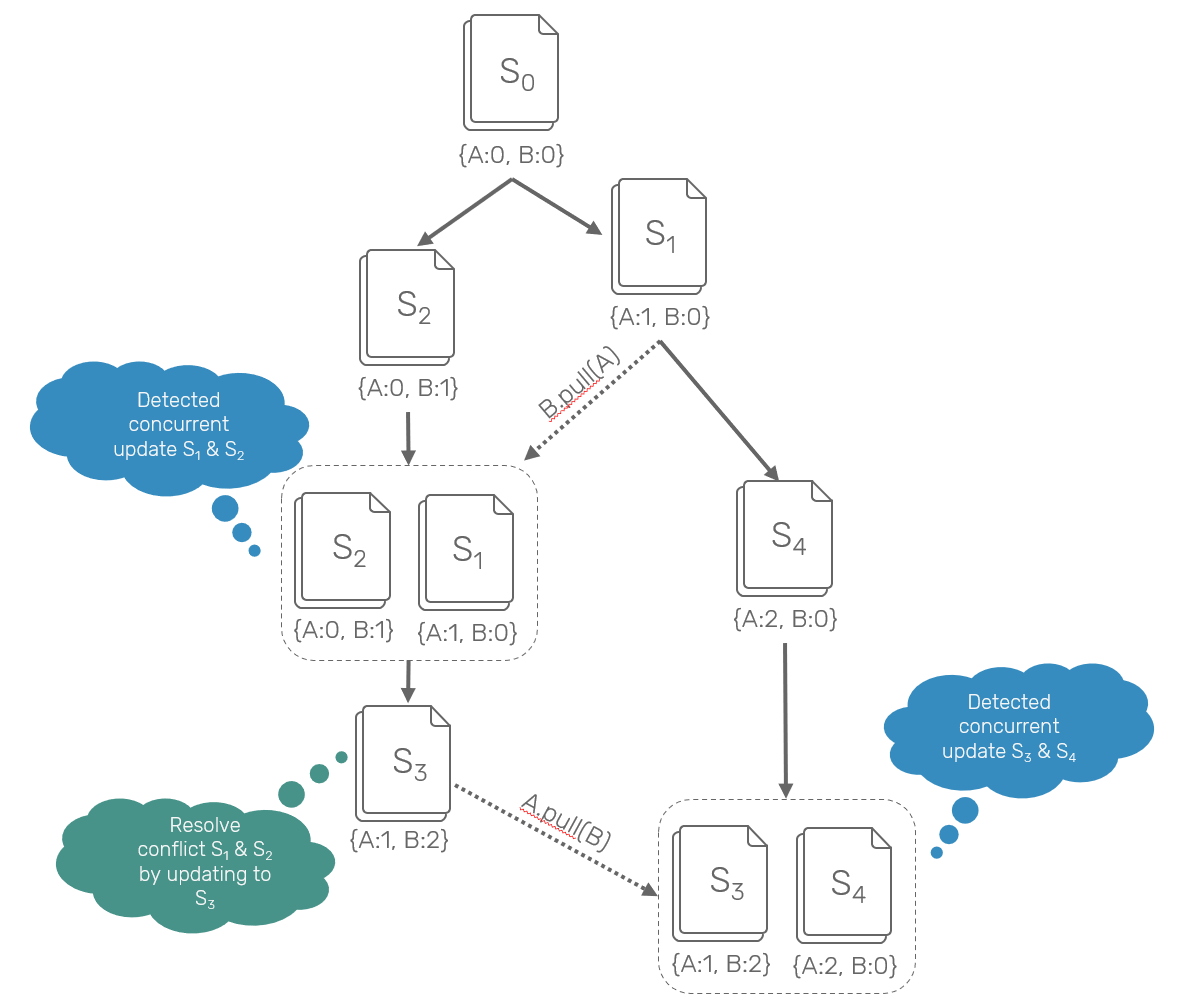
Now, let's analyse what's happening over here:
1. We consider two actors: Alice and Bob. They both start with empty register at state S0.
2. Independently and without knowing about each others intentions, Alice modifies register to state S1, while Bob does the same to state S2.
3. Bob pulls changes from Alice and discovers that she also has changed the document: he sees both changes (S1 and S2). Now, he decided to resolve these to a single value of S3.
4. While Bob tried to reconcile the conflict, Alice has overriden her state again into S4.
5. Now Alice is pulling Bob's changes, and notices that there's another conflict (S3 vs S4). What's important here is that she is not aware of the previous one (S1 vs S2) ever happening as it has been already solved by Bob.
All of that is possible thanks to version vectors (eg. {A:1,B:2}), which inform us about the relationships between the corresponding changes: whether they happened one after another or have they happened concurrently with each other.
How to represent that in code? We'll simply keep list of all concurrent values, each of them tagged with a version vector describing their causal relationships.
[<RequireQualifiedAccess>]
module MVRegister
// in order to make our register "clearable" we use an option type
// as attached vector version must be still kept to ensure that
// no previous value will override our 'clear' update
type MVRegister<'a> = (VTime * 'a voption) list
type Endpoint<'a> = Endpoint<MVRegister<'a>, 'a voption, 'a voption>
let private crdt : Crdt<MVRegister<'a>, 'a list, 'a voption, 'a voption> =
{ new Crdt<_,_,_,_> with
// at the begining our register is empty
member _.Default = []
// return list of (possibly conflicting) values alone
member _.Query crdt =
crdt
|> List.choose (function (_, ValueSome v) -> Some v | _ -> None)
// we don't need to do anything here, as version vector
// will be attached inside of Event type
member _.Prepare(_, value) = value
// prune all values, retaining only those which were updated
// concurrently to a current event
member _.Effect(existing, e) =
let concurrent =
existing
|> List.filter (fun (vt, _) -> Version.compare vt e.Version = Ord.Cc)
(e.Version, e.Data)::concurrent }
let props db replica ctx = replicator crdt db replica ctx
let updte (value: 'a voption) (ref: Endpoint<'a>) : Async<'a voption> = ref <? Command value
let query (ref: Endpoint<'a>) : Async<'a voption> = ref <? Query
You may see, that in Effect method we're only going to keep around values with concurrent version vectors. However comparison of these can yield one of 4 different outputs:
Ord.Ltmeans that we can discard the value as it has been overridden (merge resolved in Git terms) by current update.Ord.Eqis not possible, as version vectors are globally unique and no previously existing value could have the same one as current one - we don't worry about duplicates as our Reliable Causal Broadcast protocol used for event replication keeps them in check.Ord.Gtis also not possible - again this is an advantage of using RCB replication protocol, which makes sure that events which are strictly greater will never be processed first.Ord.Cc(marking a concurrent update) is the only remaining option in this situation. It represents unresolved conflicts.
With these new registers in our arsenal, let's move to defining our first collection type.
Sets
Now, we're going to cover how to build the most basic operation-based CRDT collection: a set. In the past we already covered a huge amount of theory - spanned over 2 blog posts (1, 2) - needed to implement state-based sets efficiently. Thankfully, operation-based variant is much simpler.
First the representation of the set itself consists only of pairs of values and their corresponding timestamps (here represented as version vector type VTime), which tell us when given value was added to set.
type ORSet<'a> when 'a: comparison = Set<'a * VTime>
Keep in mind that the same value could have been added multiple times - here for simplicity reasons (preferrably this should be a Map<'a, Set<VTime>>), we'll just keep them separately and deduplicate them when user requests for the state. Luckily inherent set property (uniqueness of elements) will take care of it for us:
let private crdt : Crdt<ORSet<'a>, Set<'a>, Command<'a>, Operation<'a>> =
{ new Crdt<_,_,_,_> with
member _.Query(orset) = orset |> Set.map fst
// other methods ...
}
Next, we need to support two most common operations, without which our set wouldn't be very useful: addition and removal. We can represent those as following commands (user requests) and events (actual data to be stored and replicated):
type Command<'a> =
| Add of 'a
| Remove of 'a
type Operation<'a> =
| Added of 'a
| Removed of Set<VTime>
You may notice that these corresponding types are not the same - Removed event doesn't contain information about removed element, instead it uses a collection of vector versions. Why?
- As events are often serialized and pushed through various I/O boundaries (either on disk or through the network), we don't want to put potentially heavy user data together with them when not necessary.
- In order to safely remove element we need to establish the causality relations between
Removedevent and potential additions that may have happened concurrently. For this reason we need to keep version vectors around - eachVTimeallows us to uniquely identify correspondingAddedoperation so that later on, when we're about to remove an element, we don't by accident delete the same elements that were added again concurrently to our removal.
Now let's split handling of additions and removals. Let's go with addition first:
let private crdt : Crdt<ORSet<'a>, Set<'a>, Command<'a>, Operation<'a>> =
{ new Crdt<_,_,_,_> with
member _.Prepare(orset, cmd) =
match cmd with
| Add item -> Added item
| Remove item -> // ...
member _.Effect(orset, e) =
match e.Data with
| Added(item) -> Set.add (item, e.Version) orset
| Removed(versions) -> // ...
// other methods ...
}
Command handler is simply reassigning an item from command into event data type. Applying the event itself attaches timestamp, which was generated by underlying replication protocol to uniquely identify that event. PS: ability to elevate timestamps generation into underlying infrastructure simplifies a lot of things in operation-based CRDTs.
Now, onto removals. Here the code is a bit more complicated. Preparing an event requires us to gather all vector versions of the element to be removed. Once this is done, we're ready to emit our event:
let private crdt : Crdt<ORSet<'a>, Set<'a>, Command<'a>, Operation<'a>> =
{ new Crdt<_,_,_,_> with
member _.Prepare(orset, cmd) =
match cmd with
| Add item -> //...
| Remove item ->
let timestamps =
orset
|> Set.filter (fun (i, _) -> i = item)
|> Set.map snd
Removed timestamps
// other methods ...
}
When we're about to apply our events, we again go over our set looking for all entries, which have timestamps matching the one from passed element itself, and get rid of them:
let private crdt : Crdt<ORSet<'a>, Set<'a>, Command<'a>, Operation<'a>> =
{ new Crdt<_,_,_,_> with
member _.Effect(orset, e) =
match e.Data with
| Added(item) -> // ...
| Removed(versions) ->
orset |> Set.filter (fun (_, ts) -> not (Set.contains ts versions))
// other methods ...
}
This way we're only truly remove element, if it wasn't added concurrently on other nodes. This means that our set maintains Add Wins semantics (in case when the same element was both inserted and removed on two nodes at the same time, it will remain in the set).
Summary
Remember, that you can always use this snippet to experiment and checkout these ideas by yourself. With counters, registers and sets at our disposal, we're going to move to more advanced collections in the upcoming blog posts.
Comments