In this blog post we'll continue on topic of operation-based CRDTs and focus on the optimizations and approach known as pure operation-based CRDTs: how can we use them to address some of the problems related to partially ordered event logs and optimize size of our data structures.
Other blog posts from this series:
- An introduction to state-based CRDTs
- Optimizing state-based CRDTs (part 1)
- Optimizing state-based CRDTs (part 2)
- State-based CRDTs: Bounded Counter
- State-based CRDTs: Maps
- Operation-based CRDTs: protocol
- Operation-based CRDTs: registers and sets
- Operation-based CRDTs: arrays (part 1)
- Operation-based CRDTs: arrays (part 2)
- Operation-based CRDTs: JSON document
- Pure operation-based CRDTs
- CRDT optimizations
If you tracked down this series (or were just interested by the topic on your own), you may notice that CRDTs are usually exposed as 1. data types with metadata combined with 2. replication protocol. State- and operation-based implementations shuffle complexity between these two. The more guarantees and metadata we can attach at protocol level the less we need them at data type side. Pure operation-based CRDTs could be considered to stay at the very end of protocol-complexity (in logical sense, not necessarily implementation-wise) of this spectrum: here we'll define a replication protocol that will allow us to establish a great number of guarantees about the state of the distributed system. In return it will allow us to write our data type definitions in maximally succinct manner.
Rationale behind pure operation-based CRDTs
An original paper that introduced notion of pure operations, proposed solution to several problems of traditional operation-based CRDTs:
- Reduce an amount of metadata kept together with the state. Being able to independently resolve concurrent conflicts may require additional information and CRDTs are infamous from keeping a lot of metadata, which can potentially outweigh the actual payload.
- Events pruning. Once an event (eg. removing value from the set) has been applied on all replicas in the system we want to be able to eventually delete it. Determining when it's safe to do so without any consensus algorithm is not an easy task.
The idiom "pure" comes from the fact that in this implementation, there's no more distinction between commands and events, only operations. If you remember, we had this distinction in operation-based CRDTs because while our user-facing commands were stripped of CRDT-specific metadata (which was not exposed to the client), different data structures had custom requirements that could not be generalized. In pure variant, we'll get rid of this - we won't need commands, events or command handlers.
For the reasons described above we no longer stick to eventsourcing terminology used before - it's still possible to implement our solution on top of event log, this time we'll go with a simpler approach. But before we do so, first we need to understand concept of causal stability.
Causal stability
When we're building a partially ordered log of operations, at some point we need to answer the question: when is it safe to prune events? When we talk about logs with a total order (all replicas store events in exactly the same order eg. Kafka) we can use so called commit offset that allows us to determine, up to which position in a log all replicas are in sync. This commit offset tells us when it's safe to snapshot our state and then delete events.
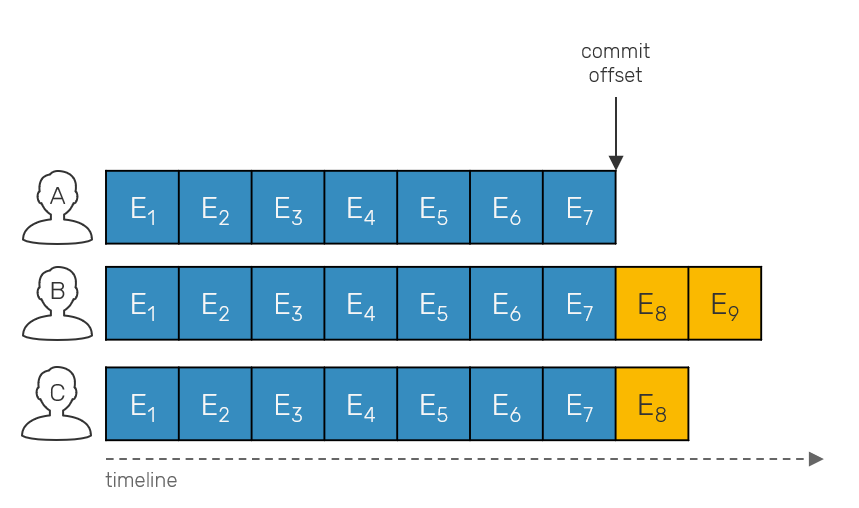
Once we drop total order, things start to get more complicated. Partially-ordered logs can have the same events under different offsets in a their local log. We track individual events with vector clocks, as they allow us to track causality aka. happened-before relationships between events required by this approach.
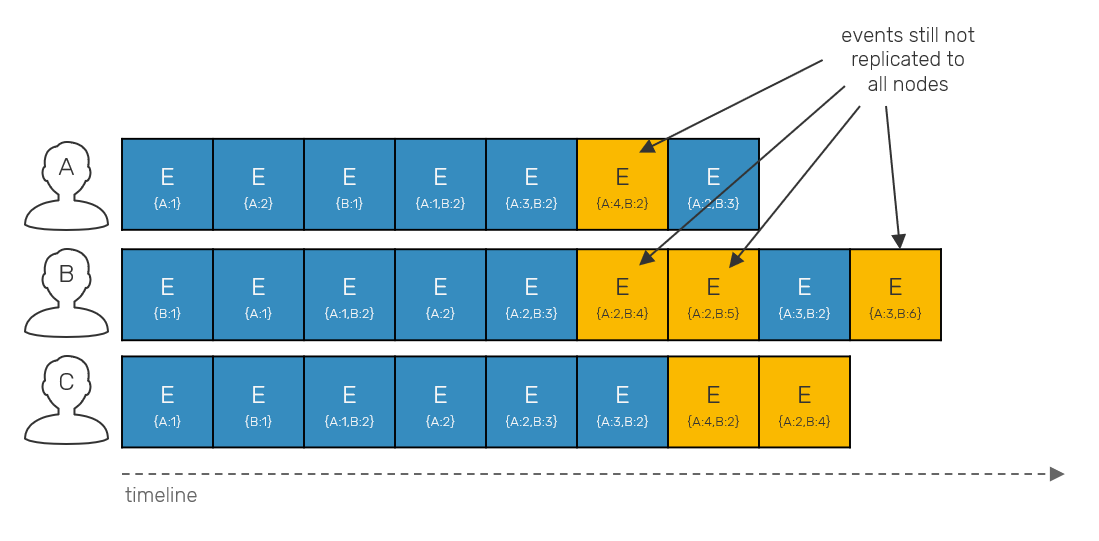
We talked about vector clocks a lot over this blog post series, and you really should have solid grasp on them before we move forward. The initial problem which we need to solve, is how to tell when event was replicated on all sides in partially ordered log?
Keep in mind that we cannot require any form of voting or arbitrary leader to solve this problem - our system is leaderless, which means that every replica needs to work in read-write manner on its own, even when disconnected from the rest of the system. Since machines cannot synchronize with each other, they must infer the safe point on their own, based only on incoming metadata.
If you remember our previous operation-based CRDT protocol implementation, we timestamped each event with a vector clock. It's used for ordering, but it also conveys more information. It tells us what was the observed state of the world from perspective of its emitter at the time it was produced. Now, we know that an event is safe to be deleted once it has been received by all replicas. How can we tell that event has been observed by everyone without explicitly asking them? Look at the incoming timestamps and let the mystery unravel.
Vector clocks define a merge method, which lets us generate the latest version of two given vectors by picking the maximum sequence numbers of their corresponding entries. This has sense, as these values are only incremented over time, so the highest sequence number in vector clock will always be more up-to-date. However, what will happen when instead of picking maximum, we pick minimum values of the corresponding vector clock entries? The resulting vector clock will describe a point in (logical) time seen by both emitters. If we'll fold this minimum over all most recent timestamps received from all replicas, what we get is the timestamp that describes the point in time seen by everyone - so called stable timestamp.
This timestamp serves us as a check point - since we know that all events prior to it have been acknowledged by all replicas. This also means, that there are no operations in flight that could possibly happen concurrently to a stable timestamp. It's important property, which we'll use later.
In order to keep track of vector clocks arriving from different replicas, we can use so called Matrix Clock - it's just a map of all replicas and their corresponding timestamps:
/// Matrix clock.
type MTime = Map<ReplicaId, VTime>
[<RequireQualifiedAccess>]
module MTime =
let min (m: MTime): VTime =
Map.fold (fun acc _ v -> Version.min acc v) Version.zero m
let max (m: MTime): VTime =
Map.fold (fun acc _ v -> Version.max acc v) Version.zero m
let merge (m1: MTime) (m2: MTime) : MTime =
(m1, m2) ||> Map.fold (fun acc k v ->
match Map.tryFind k acc with
| None -> Map.add k v acc
| Some v2 -> Map.add k (Version.merge v v2) acc)
let update (nodeId: ReplicaId) (version: VTime) (m: MTime) =
match Map.tryFind nodeId m with
| None -> Map.add nodeId version m
| Some v -> Map.add nodeId (Version.merge version v) m
Tagged Stable Causal Broadcast protocol
The basic protocol behind pure operation-based CRDTs is called Tagged Reliable Causal Broadcast or Tagged Stable Causal Broadcast. The name comes from the fact that we expose part of machinery responsible for tagging events (vector timestamps) in the user API. If you recall, we already did that in the previous implementation, for practical reasons. Moreover we could just modify the same protocol a little, but this would mean that we'd carry all cruft, that's unnecessary here. Instead let's build something simpler.
As always, we're only presenting crucial snippets here. If you want to see a full source code, use this link.
The core object, we're going to use is an Event:
[<CustomComparison;CustomEquality>]
type Event<'a> =
{ Value: 'a
Version: VTime
Timestamp: DateTime
Origin: ReplicaId }
member this.CompareTo(other: Event<'a>) =
match Version.compare this.Version other.Version with
| Ord.Cc -> // if versions are concurrent, compare other fields
match this.Timestamp.CompareTo other.Timestamp with
| 0 -> this.Origin.CompareTo other.Origin
| cmp -> cmp
| cmp -> int cmp
While the original paper only discusses values and vector versions, here we'll also add system clock timestamps together with ID of the event emitter. Thanks to them we're able to properly order even concurrent events. It's also required to implement some data types like Last Write Wins Registers or Indexed Sequences.
You can also notice that we no longer attach any sequence numbers to events - we did so in the past to be able to efficiently scan events in our persistent store. Since now we'll be able to prune events efficiently, our event log will be much shorter though. Also in this implementation usually will need to scan all non-pruned events anyway.
One of the core concepts behind pure CRDTs is the ability to split their state in two:
- A stable state represents compacted information from events that happened up to a stable timestamp. What's important here is that, because we know that there are no events concurrent to a stable vector version, we don't need any metadata associated with them, as we won't have any conflicts to resolve. This helps us to drastically reduce memory overhead.
- An unstable state represents events, which happened after stable vector version and have not been confirmed to be received by all replicas.
As more and more replication events arrives from all sides, our stable version moves forward and when that happens we're able to prune events from unstable log and apply them to a stable state snapshot. Here for simplicity we'll keep both of them as in memory objects. For practical implementation, you most likely want to persist them.
type State<'state,'op> =
{ Id: ReplicaId // id of current replica
Stable: 'state // stable state
Unstable: Set<Event<'op>> // operations waiting to stabilize
StableVersion: VTime // last known stable timestamp
LatestVersion: VTime // most up-to-date vector timestamp
Observed: MTime // vector versions of observed universe
Connections: Map<ReplicaId, (Endpoint<'state, 'op> * ICancelable)> }
We start by defining how to update our state locally. We'll do it by sending a single Submit message with user-defined operation, that's stripped of any specific metadata internal to the system.
let apply (crdt: PureCrdt<'state,'op>) (state: State<'state,'op>) =
if Set.isEmpty state.Unstable
then state.Stable
else crdt.Apply(state.Stable, state.Unstable)
let rec active (crdt: PureCrdt<'state,'op>) (state: State<'state,'op>) (ctx: Actor<Protocol<'state,'op>>) = actor {
match! ctx.Receive() with
| Submit op ->
let sender = ctx.Sender()
let version = Version.inc id state.LatestVersion
let observed = state.Observed |> MTime.update id version
let event =
{ Version = version
Value = op
Timestamp = DateTime.UtcNow
Origin = id }
let pruned =
state.Unstable
|> Set.filter (fun o -> not (crdt.Obsoletes(event, o)))
let state = { state with
Unstable = Set.add event pruned
LatestVersion = version
Observed = observed }
sender <! (apply crdt state) // respond with new state view
return! active crdt state ctx
What we're doing here is simply creating a new event with an incremented version and adding it to an unstable set - ignoring a single node systems, we can tell that this event was not yet received by all replicas (therefore cannot be applied into stable state) because we just created it. We also check if newly created event doesn't obsolete any other events we already have in our log.
What does obsolete even mean in this context? This is a tricky part as it depends on what actual CRDT implementation we talk about, but in principle keep in mind that unstable events can be in different causal relationships to each other - they can be concurrent or happen strictly one after another. In some cases it's useless to keep an event eg. if we have last-write-wins register, every event assigning a new value to the register obsoletes all older events. We can simply remove them as they're no longer needed.
Next, let's go into replication protocol. To make replication possible we'll need a set of serializable messages, like:
type Protocol<'state,'op> =
| Replicate of ReplicaId * VTime
| Reset of from:ReplicaId * Snapshot<'state>
| Replicated of from:ReplicaId * Set<Event<'op>>
| ReplicateTimeout of ReplicaId
// other messages not related to replication prodecure
The idea is simple:
- Node A wants to check if node B has some new events to be replicated (pull-based model). It sends a
Replicaterequest with its latest known vector version. - When node B receives replication request it can verify attached timestamp against its own stable version:
- If A's latest version is equal or behind B's stable version it means, that sending B's unstable events is not enough as it doesn't send all of the information. We also need to send a snapshot of a stable state - it does so in
Resetmessage. It's also necessary when fresh node joins the cluster of replicas.
- If A's latest version is equal or behind B's stable version it means, that sending B's unstable events is not enough as it doesn't send all of the information. We also need to send a snapshot of a stable state - it does so in
- B filters out all of its unstable events that happened after or concurrently to vector version received in
Replicaterequest and sends them back in aReplicatedmessage. - If response didn't arrive before expected timeout, a
ReplicateTimeoutsignal will trigger and we'll repeat our request again back from point 1.
So, with this conceptual description in mind, let's see how this could look in code:
let rec active crdt state ctx = actor {
match! ctx.Receive() with
| Replicate(nodeId, filter) ->
let (replyTo, _) = Map.find nodeId state.Connections
if Version.compare filter state.StableVersion = Ord.Lt then
replyTo <! Reset(id, toSnapshot state) // step 2.1 - send a snapshot
// send events in batches no bigger than 100 at a time
let batch = ResizeArray(100)
for op in state.Unstable do
if Version.compare op.Version filter > Ord.Eq then
batch.Add op
if batch.Count >= 100 then
// step 3 - send events which need replication
replyTo <! Replicated(id, Set.ofSeq batch)
batch.Clear()
if batch.Count > 0 then
replyTo <! Replicated(id, Set.ofSeq batch)
return! active crdt state ctx
// handlers for other messages
We replicate by sending batches of operations, since we cannot guarantee their upper bound. These batches can be prepended by a Reset message with a snapshot if necessary. But what does this snapshot consists of?
type Snapshot<'state> =
{ Stable: 'state
StableVersion: VTime
LatestVersion: VTime
Observed: MTime }
let rec active crdt state ctx = actor {
match! ctx.Receive() with
| Reset(nodeId, snapshot) when Version.compare snapshot.StableVersion state.LatestVersion = Ord.Gt ->
let state =
{ state with
Stable = snapshot.Stable
StableVersion = snapshot.StableVersion
LatestVersion = Version.merge state.LatestVersion snapshot.StableVersion
Observed = MTime.merge snapshot.Observed state.Observed }
return! active crdt state ctx
| Reset(nodeId, snapshot) -> return! active crdt state ctx // ignore
// handlers for other messages
Since Reset can be used by a new replica just joining a system (it can be also used when combined with persistence to reinitialize current replica state from persistent store), we need to supply not the state alone, but also all of the corresponding context - most notably stable version describing the timestamp of state being sent and a matrix clock which describes a timespace of known replicas, so that our receiver will be able to make its own progress in gradually advancing what the upcoming stability point may be.
Also keep in mind that when a Reset is incoming, we should check if it's still actual on the receiver side - we use asynchronous message passing, so between request/response roundtrip we might have got another update from other replicas. The open question here is what will happen if the Reset that we got has stable version which is concurrent to our own? It's a sign of either bug or malicious behavior from one of the replica - one of the properties of stable timestamp is that we can be sure that there are no events in flight that might be concurrent to it.
Arguably, handling the incoming replicated events on the receiver side is the most complex piece here.
let stabilize (state: State<'state,'op>) =
let stableTimestamp = MTime.min state.Observed
let stable, unstable =
state.Unstable
|> Set.partition (fun op -> Version.compare op.Version stableTimestamp <= Ord.Eq)
(stable, unstable, stableTimestamp)
let rec active (crdt: PureCrdt<'state,'op>) (state: State<'state,'op>) (ctx: Actor<Protocol<'state,'op>>) = actor {
match! ctx.Receive() with
| Replicated(nodeId, ops) ->
let mutable state = state
let actual = ops |> Set.filter (fun op -> Version.compare op.Version state.LatestVersion > Ord.Eq)
for op in actual do
let observed = state.Observed |> MTime.update nodeId op.Version
let obsolete = state.Unstable |> Set.exists(fun o -> crdt.Obsoletes(o, op))
let pruned = state.Unstable |> Set.filter (fun o -> not (crdt.Obsoletes(op, o)))
state <- { state with
Observed = observed
Unstable = if obsolete then pruned else Set.add op pruned
LatestVersion = Version.merge op.Version state.LatestVersion }
let stableOps, unstableOps, stableVersion = stabilize state
let state =
if not (Set.isEmpty stableOps) then
// advance with stable state
let stable = crdt.Apply(state.Stable, stableOps)
{ state with Stable = stable; Unstable = unstableOps; StableVersion = stableVersion }
else
state
let state = refreshTimeout nodeId state ctx
return! active crdt state ctx
So, again we need to start by filtering out events that might be behind local version by the time they arrived to the receiver. Then we update our observation (matrix clock) with event's own version and eventually we also need to check if incoming events are not obsoleted by the unstable events we already received and vice versa.
The final step of our Replicated handler is about stabilizing the state - once we got new events from another replica, we can improve our knowledge about what other events has this replica received/observed, thanks to the vector clocks attached to incoming events. With that knowledge we can set new stable timestamp and use it to filter out all events we considered unstable so far and promote them to a stable set. Finally we can apply them to our new state and forget about them. If you use persistent store here, this is a step when you want to store new system snapshot and delete (now stable) events.
Pure CRDTs implementations
With a replication protocol defined, now it's the time to talk about actual CRDT implementations. First, in order to nest them, we need some common API between our data types and replication protocol. As you've might already seen it, it can be condensed to few methods:
type PureCrdt<'state, 'op> =
abstract Default: 'state
abstract Obsoletes: Event<'op> * Event<'op> -> bool
abstract Apply: state:'state * operations:Set<Event<'op>> -> 'state
Default (zero) state is quite obvious as there's no single initialization point in system and all nodes can execute updates independently from each other.
We also already mentioned that obsolete method is used to check if either replicated or unstable events are redundant in result of new event replication/emission. Some pure CRDT definitions never obsolete their own events - don't conflate stable with obsolete events.
We also mentioned state application - here we're passing entire non-empty set of unstable events at once. In most cases it'll boil down to Set.fold, but in case of registers we need awareness of other unstable events during application. We're using in-memory sets here, but if you want to make it persistent, the event log could be also presented as an asynchronous sequence for purpose of this method.
As you'll see implementing actual CRDTs using this API leads to extremely concise code, all thanks to the guarantees we're able to provide at protocol level.
Counter
In case of our counter both our state and operation is just a simple number (positive or negative) and all we need to do is to sum all unstable operations on top of state to get a counter value.
let counter =
{ new PureCrdt<int64, int64> with
member this.Default = 0L
member this.Obsoletes(o, n) = false
member this.Apply(state, ops) =
ops
|> Seq.map (fun o -> o.Value)
|> Seq.fold (+) state }
Since counter updates are always independent, they never obsolete each other.
Last-Write-Wins register
Another structure is Last-Write-Wins register. Here our state is an option of contained type (as we start with uninitialized value), while operation is an instance of this type.
let inline comparer (o: Event<_>) = struct(o.Timestamp, o.Origin)
let lwwreg =
{ new PureCrdt<'t voption, 't> with
member this.Default = ValueNone
member this.Obsoletes(o, n) = comparer o > comparer n
member this.Apply(state, ops) =
let latest = ops |> Seq.maxBy comparer
ValueSome latest.Value }
We take advantage of Event<> fields defined before, which carried over system timestamp. Now we can use it to determine which operation is "the most recent one". Since we cannot exclude risk, that that two different events will have the same timestamp, we additionally use origin field - ID of replica, where operation was submitted - to distinguish them, effectively making our timestamp look like Lamport Clock.
Just as we mentioned previously, assignment event obsoletes older ones if its timestamp (see: comparer function above) is higher than any other.
Multi-Value register
Multi-Value Registers seems to be ideal candidates for our implementation here, as they are always returning all concurrently updated values - which in our case is simply an unstable set!
let mvreg =
{ new PureCrdt<'t list, 't> with
member this.Default = []
member this.Obsoletes(o, n): bool = Version.compare n.Version o.Version <= Ord.Eq
member this.Apply(state, ops) =
ops
|> Seq.map (fun o -> o.Value)
|> Seq.toList }
Here we can also obsolete older events, but unlike in the case of Last-Write-Wins register, here we define "older" in context of logical time (vector clocks) rather than physical one. Keep in mind that Apply method here doesn't take old state into account - since we made sure that unstable operations are never empty, they always represent elements assigned later than stable state and therefore override it.
Add-Wins Observed Remove set
For pure OR-Set, we can focus on two basic operations - add and remove element from the set. Application of unstable operation is again very simple: we just add an element to the set when we see Add operation, and remove it when Remove was detected.
type Operation<'t when 't:comparison> =
| Add of 't
| Remove of 't
let orset =
{ new PureCrdt<Set<'t>, Operation<'t>> with
member this.Apply(state, ops) =
ops
|> Set.fold (fun acc op ->
match op.Value with
| Add value -> Set.add value acc
| Remove value -> Set.remove value acc) state
member this.Default = Set.empty
member this.Obsoletes(o, n) =
match n.Value, o.Value with
| Add v2, Add v1 when Version.compare n.Version o.Version = Ord.Lt -> v1 = v2
| Add v2, Remove v1 when Version.compare n.Version o.Version = Ord.Lt -> v1 = v2
| Remove _, _ -> true
| _ -> false }
Obsolete mechanism is about checking if two operations apply to the same logical element and (if so) if one of them is directly behind another. So Add(t1, a) will obsolete Add(t0, a) if t0 < t1 because we cannot add the same element twice - so we'll just keep the more recent operation in our unstable set.
For removals we preserve add-wins semantics - if two add/remove operations are in concurrent update conflict, we'll prefer to Add an element. What's worth noticing here, our Remove operation will never really be present in unstable set. Since we obsoleted older operations by more recent ones, the only remaining ones in our unstable set could be concurrent updates - and as we said in case of any concurrent conflict we always prefer Add over Remove, hence we can get rid of Remove all together. The only exception from this rule is a unstable set with a single Remove element.
Indexed Sequence
We'll finish discussion about pure CRDTs with Indexed Sequence implementation. It's hard to say if it's really an LSeq, RGA or any other known data structure, as it doesn't really bear any characteristic attributes of original non-pure implementation nor was it defined in original paper.
Reminder: what differs indexed sequences from sets is that they allow users to specify order in which elements are to be inserted rather than relying on natural order of comparable elements. For this reason, we need to be able to resolve conflicts like different replicas inserting/deleting different values at the same index concurrently.
Thankfully, the pure-based variant is even simpler than OR-Set here. Just like in case of OR-Set, operation application is just straightforward insert/remove action done when a corresponding operation is applied.
type Operation<'t> =
| Insert of index:int * value:'t
| Remove of index:int
let iseq =
{ new PureCrdt<'t[], Operation<'t>> with
member this.Apply(state, ops) =
ops
|> Set.fold (fun acc op ->
match op.Value with
| Insert(idx, value) -> Array.insert idx value acc
| Remove idx -> Array.removeAt idx acc) state
member this.Default = [||]
member this.Obsoletes(o, n) = false }
Few important notes here:
- Obsolete method is not necessary here, as we didn't defined any update method over existing elements. Since unstable event log grows or shrinks dynamically as replication is in progress we don't really want to obsolete removals, as they may be needed later on to undo inserts.
- What's crucial here is the characteristic of an unstable set (
opsparameter) - in our case it's a set of events ordered by vector version, then timestamp, then origin. This is the reason why we don't need virtual pointers, that we used in LSeq implementation in the past. Order of events in unstable set will eventually be the same on all replicas. When applying events over stable state, we keep that order. This allows us to guarantee that we won't mess the indexes of concurrent updates (represented by unstable set itself).
Keep in mind that above implementation is not free of interleaving issues, which may be problem is some use cases like collaborative text editing.
Eviction
We talked a lot about strong sides of pure operation-based CRDTs so far. But if it's so great, why are they so uncommon, so rarely used in real systems? There's a one hard problem, they introduce. Ability to determine stability point may not require explicit coordination, but it does require nodes to communicate with each other. If at least one node in the cluster goes offline and never gets back up, we're no longer able to stabilize our state.
Unfortunately this is quite common scenario for applications working at the edge: which is one of the most popular use cases for having CRDTs. Moreover problem of detecting dead nodes (like permanently dead ones) is hard to automatize without introducing risk of data loss in cases when our assumptions about dead node were invalid.
Here, we'll shortly cover the possible workaround that is node eviction (AFAIK it was not described in any paper). We're going to send a signal to inform that a given node no longer takes part in a replication process, and from now on, all of its concurrent updates will be ignored unless its willing to sync by reseting its state. This is something that could be done manually by an operator (eg. moderator of chat removing inactive users) or automatically (evict nodes that didn't respond within a given timeout). Keep in mind that trying to automate this process may be risky and not possible at all in some cases - while it seems doable for cross-datacenter systems, edge devices often cannot provide required properties to make this approach practical.
Here we're going to extend protocol we implemented with two extra messages: Evict and Evicted. Here we assume approach where evict is being send to a replica explicitly from outside. Actor, which received it is going to create an Evicted message with new vector timestamp and broadcast it to all other connected replicas. It will also remember which node was evicted at what timestamp.
let broadcast msg state =
for e in state.Connections do
(fst e.Value) <! msg
let rec active crdt state ctx = actor {
match! ctx.Receive() with
| Evict nodeId ->
let version = Version.inc state.Id state.LatestVersion
let msg = Evicted(nodeId, version)
broadcast msg state
let connections = terminateConnection nodeId state
let observed =
state.Observed
|> Map.remove nodeId
|> Map.add state.Id version
let state = { state with
LatestVersion = version
Evicted = Map.add nodeId version state.Evicted
Observed = observed
Connections = connections }
return! active crdt state ctx
// other handlers
Why do we need to generate a new vector version? We're going to use it as a boundary. When it will be received on other nodes we have 3 cases to handle for incoming or unstable events (we can ignore equality as no event timestamp will be equal to it):
- Events that happened before this eviction timestamp will eventually be applied into stable state. We cannot really prevent that as different nodes stabilize at different rates.
- As a tradeoff we'll also accept and eventually apply events which happened directly after eviction version. It represents a scenario, when a node was evicted, resets its state and joined again. This comes with a risk - we'll discuss it in a minute - but it also lets us reuse replica identifiers. Otherwise we'd need a new replica ID every time node is evicted, and that could cause an explosion of vector clock size.
- The last case is when incoming events emitted by evicted node come with timestamps concurrent to evicted version itself. This means that we received an event from a node, which didn't yet know it was evicted. Here, we're going to drop these events. This case comes with inherent risk of data loss - we accepted an unstable event, but later revoke it.
First let's consider what would happen when node is informed about its own eviction:
let rec active crdt state ctx = actor {
match! ctx.Receive() with
| Evicted(evicted, version) when evicted = state.Id ->
// evacuate...
return Stop // stop current actor
We didn't really described "evacuate" section, as it's very context specific. How do you want to handle eviction? Maybe redirect evicted events aside, so that later - after node will reset its state - they could be reviewed and resubmitted again (as new operations). If you persisted a node state on disk, you may want to do some cleaning there as well.
What's important to remember is that - since we allowed node to reconnect if it agreed to reset its state - that there's a structural weakness here: if node recovers after eviction, its latest vector version must take into account sequence number of its ID included in evicted version - it cannot start from 0. Example: node B evicts A at time {A:1,B:2}. Node A resets its state but before its synchronized, user submitted an operation. If A after reset starts with an empty version, a newly submitted operation will have timestamp {A:1} which potentially may corrupt the state of a system, as other nodes might already seen such timestamp in the past: it's no longer unique.
Is it possible to keep previously evicted node writeable even before it updated its own state up to a given version? Yes, we could i.e. assign a temporary timestamps (eg. {A:1'}, {A:2'} ...) to locally submitted operations. These temporary events can be presented to local user, but are forbidden to replicate to remote replicas until local node synchronizes its own state up to evicted timestamp (eg. {A:1,B:2}). As new events arrive from remote nodes, we update the latest version and rewrite events with temporary timestamps on top of it (eg. latest will equal: {A:1,B:1}, with temporary version: {A:1'} → observed temporary event version: {A:2,B:1}). Once the latest version reached evicted timestamp, local replica can be considered synchronized and its temporary events can now get actual version and be send outside.
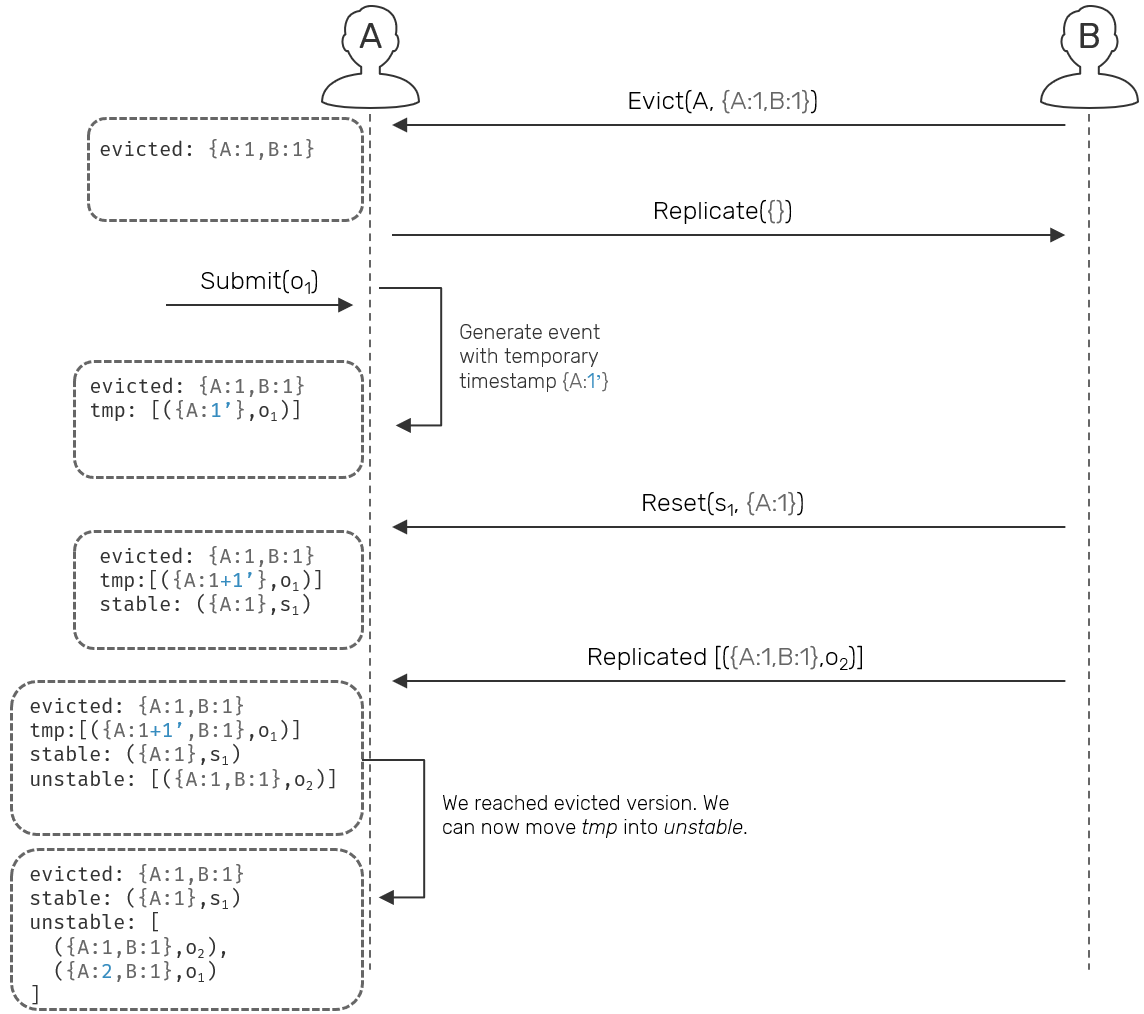
This is an idea for an eviction extension to an original tagged reliable causal broadcast protocol. We won't dive deeper than the diagram above, instead we'll focus on basic eviction process.
For other nodes, when they notice eviction, all we really need is to remember evicted node and remove unstable events originating from evicted node, which versions are concurrent to evicted timestamp.
let isEvicted version e =
e.Origin = evicted && Version.compare e.Version version = Ord.Cc
let rec active crdt state ctx = actor {
match! ctx.Receive() with
| Evicted(evicted, version) ->
let connections = terminateConnection evicted state
let unstable =
state.Unstable
|> Set.filter (fun e -> not (isEvicted version e))
let state = { state with
Evicted = Map.add evicted version state.Evicted
Observed = Map.remove evicted state.Observed
Connections = connections
Unstable = unstable }
return! active crdt state ctx
We also need to modify our Replicate/Replicated cycle a little. If we received Replicate request from evicted node with timestamp concurrent to eviction version, it means that the request was send before a node knew about being evicted. It's possible that the message never arrived to it eg. due to network failure. So what we're going to do is to simply resend it an Evicted signal.
let rec active crdt state ctx = actor {
match! ctx.Receive() with
| Replicate(nodeId, filter) ->
match Map.tryFind nodeId state.Evicted with
| Some version when Version.compare filter version = Ord.Cc ->
// inform node about it being evicted
ctx.Sender() <! Evicted(nodeId, version)
return! active crdt state ctx
| _ -> // standard handle we defined before
| Replicated(nodeId, ops) ->
let mutable state = state
let evictedVersion =
Map.tryFind nodeId state.Evicted
|> Option.defaultValue Version.zero
let actual =
ops
|> Set.filter (fun op ->
Version.compare op.Version state.LatestVersion > Ord.Eq &&
not (isEvicted evictedVersion op)) // prune evicted events
// rest of replication logic defined before
For Replicated response (which could be send concurrently to eviction), we'll simply remove all replicated events that should be evicted.
Take into account all warnings we talked about here. While far from ideal, this process offers an alternative for ever-growing unstable event log in face of disconnected or potentially dead nodes. Decision if this is a tradeoff worth taking depends on actual system at hand.
Summary
In this blog post we covered a pure operation-based variant of Conflict-free Replicated Data Types. We discussed its crucial points and weaknesses. We also implemented a core logic behind replication protocol and most common data types: counters, registers, sets and arrays. We also discussed what stability issues may arise in face of dynamically changing membership and how they could be potentially solved.
Next time we'll discuss a variety of CRDT optimizations, that could be applied to systems working on production.
Comments