Last time we were talking about partitioning in distributed systems. Now it's a time to talk about protocols that allow us to establish transactional reads and writes across partitions - which could be living on different machines.
Many of the traditional databases provide transactions with customizable isolation levels. The ones defined in ANSI SQL standard are: Serializable, Repeatable Read, Read Committed and Read Uncommitted. Later on SQL Server introduced Snapshot Isolation, which became part of this "canon". These are most renown and if you are not aware about differences and anomalies that can occur when using them, you can get quick grasp in this article or if you're looking for something more detailed, in this CMU lecture.
Problem with above isolation levels is that they were created with assumption of being run on a single process/machine. In order to be able to address the update visibility issues in distributed setting, we need other protocols such as atomic broadcast or consensus algorithms. How to combine these two groups?
Read Atomic
Here we'll cover so called Read Atomic Multi Partition (RAMP) transactions, proposed by Peter Bailis to address some of the issues of many distributed transaction protocols. The guarantees of Read Atomic isolation level are:
- Preventing dirty reads.
- Preventing dirty writes.
- Preventing read skews - which is not assured by Read Committed (a default level for many RDBMS).
The last one is especially important in the original intent of a protocol, which is used to update multiple indexes and views in consistent manner. At the same time some anomalies like write skew and lost updates are still possible. This places it at the level close to what Repeatable Read and Snapshot Isolation have to offer.
One of Read Atomic Multi Partition (RAMP) premises is synchronization independence which means that two transactions can be committed concurrently without waiting for each other to complete, giving us low latency. What happens when both of them are writing to the same entry? There are two things to it: first we use Multi-Version Concurrency Control that let's us use different snapshots of the same record. However eventually these versions must be reconciled to a single one:
- One way is to use transaction timestamps to perform Last Write Wins semantics - write from the latest transaction is persisted for the future use, while older versions will eventually discarded. This is probably the most popular approach which we'll use here as well.
- Another approach is conflict resolution via Conflict-free Replicated Data Types, which were discussed heavily on this blog post. This way we can merge different versions of the same entry from different write transactions into one.
Another RAMP property is partition independence. In short it means, that reads/writes only need to talk with partitions that contains necessary data. This means higher availability and lower cost of our transactions, making them scale better in distributed systems.
Implementation-wise, RAMP has been proposed in 3 different variants, which offer tradeoffs between metadata size and number of roundtrips necessary to read the data (writes always require two roundtrips):
- RAMP-Fast lets us guarantee, that every read transaction can retrieve entries from corresponding partitions within a single roundtrip (RTT). This however comes at a cost: in order to ensure, that we obtain a correct version of entry (so that transaction boundaries are maintained), we need to store and pass keys of all entries touched within the same transaction. If our transaction spans over many keys - or the key sizes are big - this may be quite heavy approach.
- RAMP-Small which doesn't require any extra metadata (hence name small) at the cost of requiring two roundtrips to every partition in order to realize transactional reads.
- RAMP-Hybrid that tries to create a middle ground between pt.1 & 2. Here we encode information about other transaction entries inside of a bloom filter that is then used as a metadata. We'll discuss this approach in more detail later on, but for now it's enough to say that bloom filters let us keep a constant metadata size while hybrid approach enables 1RTT transactional reads if we can ensure that versions of read entries don't collide with other transactions with fallback to 2RTT in other case.
For the scope of this blog post we'll only cover hybrid approach. The performance of it depends on the false positive ratio returned by our Bloom filter, which itself depends on its own size and number of entries written by a transaction. If you're interested in calculating an optimal size for your case, you can always use this online calculator.
The source code for a snippets we'll be referring to is available here.
MVCC
First we'll start by describing how are we going to represent data belonging to a different entries. Because our transactions are going to be executed concurrently, in a distributed environment, we can consider lock avoidance to be quite important property of our system. However since transactions are not executed instantaneously - especially if they touch data residing on different machines - we may run into scenarios of multiple concurrent dirty writes (updates that have not been committed yet).
This is where Multi-Version Concurrency Control (MVCC) comes into play. Instead of storing a single value for every entry, we're going to store multiple versions of them, one for each write may by an individual transaction.
// In practice you don't want to use Date Time but something like
// Hybrid Logical Time (see: http://bartoszsypytkowski.com/)
type TxnId = DateTime * NodeId // unique transaction identifier
type Record =
{ value: byte[] // value stored - we use Last Write Wins semantics
txnId: TxnId // a transaction timestamp for this data item
filter: Bloom } // RAMP Hybrid bloom filter
// in-memory MVCC store of a partion
let versions: Map<string, Map<TxnId, Record>>
// the latest committed transaction IDs for each entry in `versions`
let lastCommit: Map<string, TxnId>
Each partition's store is represented by a combination of Map<string, Map<TxnId, Record>> (where each entry is composed of key and collection of versioned records representing different concurrent writes) and Map<string, TxnId> which informs, which transaction was the latest one to commit every given entry.
One of the downfalls of using MVCC in your system is a fact, that you can quickly flood your store with outdated versions of the same entries. While there are many different strategies of solving this problem - some of them deserving their own articles - we're going with fairly naive vacuum process implementation, which we'll describe in a moment.
Partitions
After describing the basics of Multi-Version Concurrency Control, we're now cover how we're going to manage our data in the distributed setting. Usually when working with distributed databases, we want to scatter our data to many different nodes eg. to better utilize parallelism capabilities of multi-machine environment and to achieve higher availability. For this reason we're going to partition our data.
If you're interested more about different approaches to data partitioning, you can read about them here. Here we're going to use some simplifications to keep our blog post in reasonable size:
- We don't replicate - every record is stored only on a single partition.
- We don't manage or rebalance partitions - for the sake of example we will operate on the fixed shared view of partitions and use simple modulo hash to specify partition of an each entry.
- Each partition stores its entire subset of entries assigned to it in memory. We don't cover on-disk durability here.
In our example every partition will be represented as an actor (which has unique ID) with following state:
module Partition
type State =
{ versions: Map<string, Map<TxnId, Record>> // MVCC dictionary - entries are versioned by timestamp
lastCommit: Map<string, TxnId> // the latest committed transaction for each entry
deadlines: Map<TxnId, DateTime> // completion deadlines given each active transaction
vacuum: ICancelable option } // MVCC vacuum cleaner scheduled task
As partitions will respond to different requests and participate in 2-phase commit protocols, they must also be able to handle following messages:
module Partitions
let rec private ready (state: State) (ctx: Actor<obj>) = actor {
let! msg = ctx.Receive()
let sender = ctx.Sender()
match msg with
| Read(key, deps) -> ...
| Prepare(txn, deadline, key, value) -> ...
| Commit(timestamp, key) -> ...
| VacuumTick -> ...
}
The last one VacuumTick is a message send by partition to itself in time intervals in order to proceed with outdated entry versions cleaning, we discussed about together with MVCC. Let's cover it now.
Vacuum
This process is conceptually very similar to GCs known from languages with managed runtimes. Garbage collection described here is pretty primitive:
- We'll calculating effective deadline based on current time. We also add 1 minute grace period. Why? To amortize clock skews that could possibly happen between multiple machines.
- Find all transactions which deadline is overdue our deadline.
- Run through MVCC store and remove all versions belonging to overdue transactions, unless they are last committed entries.
We finish all of this with schedule up next VaccumTick. Don't do this at the beginning nor within repeatable intervals, as we have no idea how long will it take to complete.
| VacuumTick ->
// calculate deadline as a cutoff line for overdue transactions
let deadline = DateTime.UtcNow + TimeSpan.FromMinutes 1.
// pick transactions over the deadline
let overdue =
state.deadlines
|> Seq.choose (fun e -> if e.Value >= deadline then Some e.Key else None)
|> Set.ofSeq
// remove versioned entries belonging to overdue transactions
// unless they were the latest committed ones
let versions =
state.versions
|> Map.map (fun key versions ->
versions
|> Map.filter (fun txn item ->
match Map.tryFind key state.lastCommit with
| Some ts when ts = txn -> true // this is the last committed entry
| None -> true // this entry transaction was not yet committed
| _ -> Set.contains item.txnId overdue)
)
// schedule next vacuum
let vacuum = ctx.Schedule vacuumInterval (retype ctx.Self) VacuumTick
// cleanup overdue transactions
let deadlines =
overdue
|> Set.fold (fun acc txn -> Map.remove txn acc) state.deadlines
let state = { state with versions = versions
deadlines = deadlines
vacuum = Some vacuum }
return! ready state ctx
Keep in mind that running vacuum inside of the same actor will postpone all concurrent read/write requests until completion. Since vacuum may take long time, it's useful to put it into separate thread or introduce turn-based checkpointing mechanism. Ultimately there are many different ways on how to handle MVCC garbage collection properly, but since we don't have page and tuple IDs, we won't focus on them here.
Write transactions
First lets cover writes. Unlike in case of SQL, transactions in RAMP are non-interactive. This means that there are no separate begin/commit/abort phases visible to users. Both reads and writes are described in terms of a single operation and always require to specify all keys used by transaction up front. RAMP writes are using two phase commit protocol:
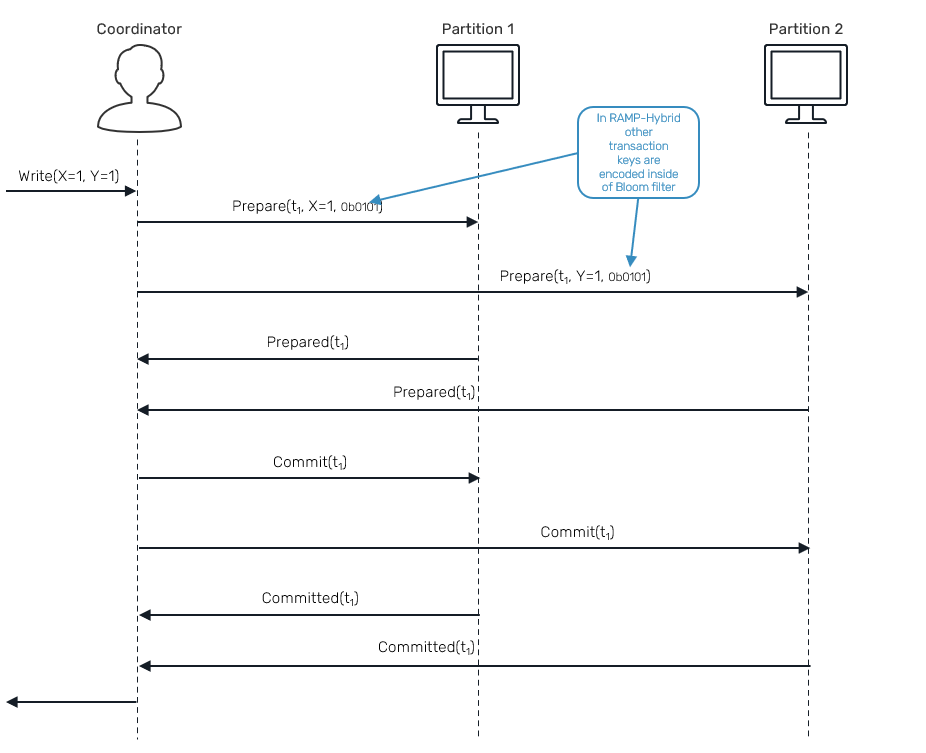
Here, we'll use a dedicated actor to serve as a write transaction coordinator:
module WriteCoordinator
type State =
{ txn: TxnId // write transaction ID
total: int // total number of entries
remaining: int // number of remaining partition ACKs
partitions: Map<string,IActorRef<Message>> // partitions per key
replyTo: IActorRef<Message> }
First let's cover prepare phase: we'll start by sending a Prepare request to all partitions participating in transaction. We'll also build up a bloom filter
// all entries in scope of the transaction share the same bloom filter
let bloom =
entries // Map<key, updated value> we want to write
|> Map.keys
|> Seq.fold (fun acc key -> Bloom.add key acc) Bloom.empty
for e in entries do
let partition = keyToPartition e.Key state
let item = { value = e.Value; txnId = txn; filter = bloom }
partition <! Prepare(txn, deadline, e.Key, item)
Each partition will store affected row versions - but not commit them yet - and keep transaction deadline info for vacuum process described above.
module Partition
let rec ready (state: State) (ctx: Actor<obj>) = actor {
let! msg = ctx.Receive()
match msg with
| Prepare(txn, deadline, key, value) ->
// remember transaction deadline
let deadlines = Map.add txn deadline state.deadlines
// add prepared record to MVCC store
let versions =
Map.tryFind key state.versions
|> Option.defaultValue Map.empty
let versions =
state.versions
|> Map.add key (Map.add txn value versions)
let state = { state with versions = versions
deadlines = deadlines }
// reply back to a coordinator
ctx.Sender() <! Prepared txn
return! ready state ctx
}
Once a coordinator receives Prepared confirmation from all expected partitions, it can now send commit request:
module WriteCoordinator
let rec preparing (state: State) (ctx: Actor<Message>) = actor {
match! ctx.Receive() with
| Prepared txn when state.txn = txn ->
let remaining = state.remaining - 1
// check if we received all required Prepared messages
if remaining = 0 then
// prepare phase is complete - we can now commit
for e in state.partitions do
e.Value <! Commit(state.txn, e.Key)
return! committing { state with remaining = state.total } ctx
else
return! preparing { state with remaining = remaining } ctx
}
Since each partition already stored necessary records during the prepare phase, all we need to do is to override information about last committed transaction for a given key.
What we need to think of is that these prepare commit phases may be executed concurrently for a different transactions and they can arrive to partition at different times. This may require potential conflict resolution. Since we're using last write wins strategy, it means that we only update lastCommit table, if a previously committed transaction is younger than the one we're actually committing.
module Partition
let rec ready (state: State) (ctx: Actor<obj>) = actor {
let! msg = ctx.Receive()
match msg with
| Commit(txn, key) ->
let previous =
Map.tryFind key state.lastCommit
|> Option.defaultValue (DateTime.MinValue, 0)
let state =
// use Last Write Wins semantics - transaction with newer ID wins
// you can use CRDTs here and merge different versions instead
if previous >= txn then state
else { state with lastCommit = Map.add key txn state.lastCommit }
// reply back to a coordinator
ctx.Sender() <! Committed txn
return! ready state ctx
}
We can complete our write transaction once a coordinator received commit confirmation from all participating partitions. Here we won't deal with situations of partial failures in Commit request delivery, but if we assumed that some of the partitions have received it, we must guarantee that all of them eventually did. This may also require a coordination with vacuum process.
Read transactions
Now lets cover a RAMP-Hybrid read-only transactions. Hybrid reads can use either a fast path (requiring only one roundtrip to get all necessary data) or a slower one using two roundtrips. In general we expect slow path to be executed on rare occasions, as it's related to non-negatives returned by bloom filters of each record when checking cross-transaction key collisions.
We can represent a "happy-path" of this workflow using following diagram:
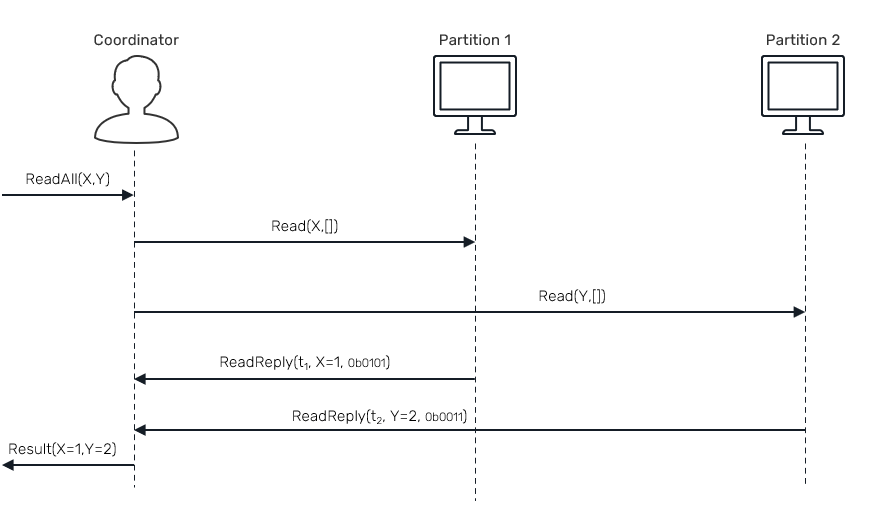
Just like in case of writes, we'll delegate transaction logic to a dedicated coordinator actor:
module ReadCoordinator
type State =
{ replyTo: IActorRef<Message>
partitions: Map<string,IActorRef<Message>> // participants
remaining: Set<string> // remaining keys to be read
result: Map<string, Record option> }
There are two rounds, and hopefully only one of them will need to be executed. In first round we're sending a read request to each partition with an empty set of dependencies - these are IDs of transactions that describe a boundaries for our read transaction expectations. However in a first round of requests we don't know them yet:
module Partition
let rec ready (state: State) (ctx: Actor<obj>) = actor {
let! msg = ctx.Receive()
match msg with
| Read(key, deps) ->
let reply =
if Array.isEmpty deps then
// 1st round
let latestTxn = Map.tryFind key state.lastCommit
let versions = Map.tryFind key state.versions
match latestTxn, versions with
| Some ts, Some versions -> Map.tryFind ts versions
| _, _ -> None
else
// 2nd round
...
sender <! ReadReply(key, reply)
return! ready state ctx
}
With no transaction ID requirements, we simply return the latest committed transactions we know about. On the read coordinator side, we gather those partial replies. Once we have all of them we check for so called "siblings". If none were found, we can return early. Otherwise we need to start second round of requests.
module ReadCoordinator
let rec round1 (state: State) (ctx: Actor<Message>) = actor {
match! ctx.Receive() with
| ReadReply(key, item) ->
let remaining = Set.remove key state.remaining
let result = Map.add key item state.result
if Set.isEmpty remaining then
// 1st round completed - we gathered all replies
let siblings = siblings result // check if we need 2nd round
if Map.isEmpty siblings then
// complete transaction
let reply =
result
|> Map.filter (fun k v -> Option.isSome v)
|> Map.map (fun k v -> v.Value.value)
state.replyTo <! ReadAllReply reply
return Stop
else
// start 2nd round
for e in siblings do
let partition = Map.find e.Key state.partitions
partition <! Read(e.Key, Array.ofList e.Value)
let remaining = siblings |> Map.keys |> Set.ofSeq
return! round2 { state with remaining = remaining } ctx
else
let state = { state with remaining = remaining; result = result }
return! round1 state ctx }
Ok, but what are those siblings? They are simply record versions gathered by our read transaction, which were part of the same write transaction in a past, but were already overridden by different writes happening concurrently on different partitions by the time we received them all.
let rec siblings (results: Map<string, Record option>) =
let mutable deps = Map.empty
for e1 in results do
for e2 in results do
if e1.Key <> e2.Key then
match e1.Value, e2.Value with
// if records belonged to different transactions and they can
// be found in each others bloom filter, return their IDs
| Some i1, Some i2 when i1.txnId > i2.txnId && Bloom.maybeContains e2.Key i1.filter ->
let ts = Map.tryFind e2.Key deps |> Option.defaultValue []
deps <- Map.add e2.Key (i1.txnId::ts) deps
| _ -> ()
deps
It basically means we detected a read skew, as we received records that were supposed to be modified by the same transaction, but instead we detected they were updated concurrently by two different ones. This can happen when we send a partial read requests to our partitions, but at least one of them was interrupted with another update before returning a read reply:
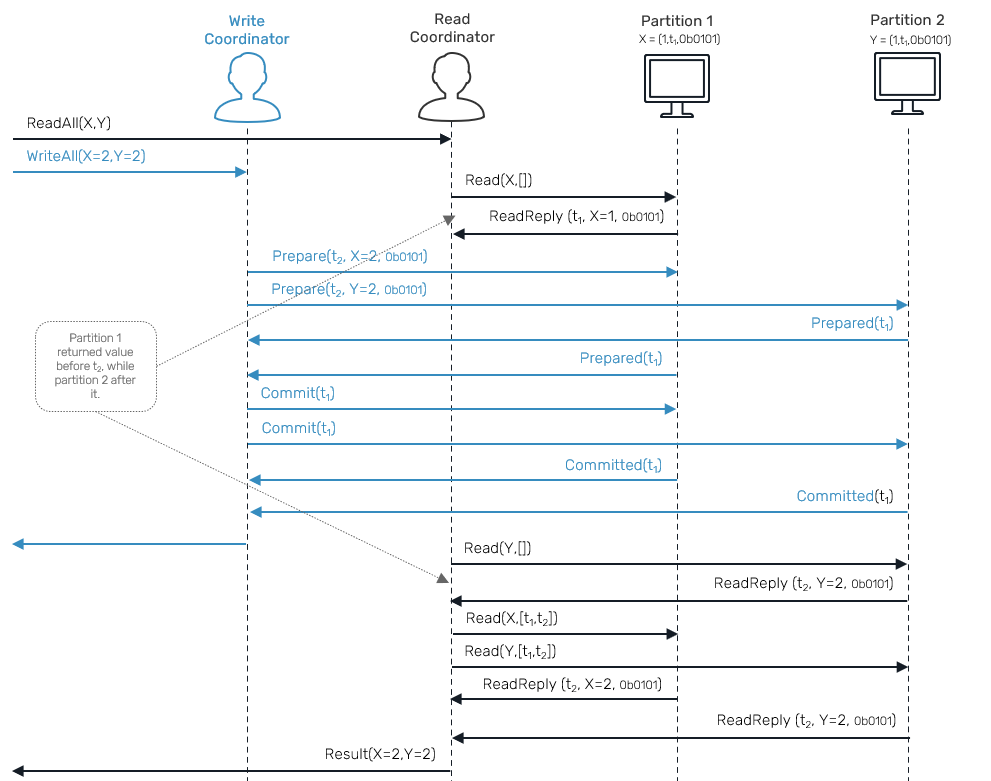
In such case we need a second round, in which we send Read request again, this time supplied with IDs of concurrent transactions we detected during 1st read round.
Since we're using bloom filters, we are not 100% sure if entries were in fact part of the same write, so we conservatively make that assumption. The result of our siblings function is a map of keys and list of concurrent write transactions.
Since we now understand what our dependencies are, let's fill a missing hole in partition Read handler:
module Partition
let rec ready (state: State) (ctx: Actor<obj>) = actor {
let! msg = ctx.Receive()
match msg with
| Read(key, deps) ->
let reply =
if Array.isEmpty deps then
// 1st round
let latestTxn = Map.tryFind key state.lastCommit
let versions = Map.tryFind key state.versions
match latestTxn, versions with
| Some ts, Some versions -> Map.tryFind ts versions
| _, _ -> None
else
// 2nd round
let versions = // get all version of an entry
Map.tryFind key state.versions
|> Option.defaultValue Map.empty
let recentTimestamps = Map.keys versions |> Seq.sortDescending
recentTimestamps
// find the most recent version satisfying the dependency
|> Seq.tryFind (fun version -> Array.contains version deps)
|> Option.map (fun version -> Map.find version versions)
sender <! ReadReply(key, reply)
return! ready state ctx
}
What we're about to do here is to take the most recent version of records that matches the transaction ID constraint we computed by siblings function - if none of the versions matched we simply return None. That matches our initial promise - we either read values after committed write transaction or prior to it, even if this means returning no value at all.
Further reading
With this knowledge of RAMP protocol in our hand, we're should be able to make distributed read/write transactions in no time. We covered here the most crucial parts necessary to implement a Read Atomic Multi Partition transaction protocol. If you're interested in further reading, I can recommend an original paper which is very legible as well as its application inside of Facebook's TAO database.
Comments