While this post is addressed to F# .NET developers, it introduces much wider concepts starting from hardware architecture to overall .NET runtime and JIT compiler optimizations. It shouldn't be a surprise - optimizing the application performance requires us to understand the relationships between our high level code and what actually happens on the hardware.
There's a popular opinion that F# code must be slower than equivalent C# code. This opinion is mostly false, however it comes with some rationale. Usually comparison doesn't use equivalent code in both languages, and F# is generally more high level and declarative in nature. "Idiomatic" F# code doesn't always play well with .NET virtual machine. Writing code that is high level, declarative and fast on .NET platform is not an easy task.
In the examples below we'll use some common tools that will help us get better insight into nature of F# code:
- Sharplab allows us to easily inspect generated JIT intermediate representation, assembly or even equivalent C# code (which sometimes is approximate, since not all IL idioms are representable in C#) for a given F# snippet. For assembly code usually some extra mangling with params may be necessary for code to be generated as SharpLab sometimes cannot introspect F# core lib code.
- Object Layout Inspector lets us see how structs and classes will actually be represented in memory.
- BenchmarkDotNet is very popular library for writing micro benchmarks. We'll use it to show heap allocations and execution times of our code.
A correct profiling of the executing application is crucial before starting any work on optimizing the code - there's no sense in shaving last possible CPU cycles out of the function that's executed for 0.1% of the time.
Keep in mind that for most day-to-day business applications, first way to solve performance problems is to reduce obvious mistakes (eg. replacing multiple I/O requests with one, writing more efficient database query etc.). If that was not the case, next step for satisfactory solution can be simply writing more imperative code - to make it easier to reason about for the compiler rather than human - or picking better-suited data structures. This is especially prevalent in F#, where we can observe pervasive usage of types like 't list (tip: if you're looking which collection to use and want good performance, F# list is almost never a good answer). Here we're about to go deeper, into area where we're about to compete with the prefabricated data types and algorithms.
Understand memory layout of value types
One of the big performance gains, that .NET runtime uses to take advantage over other managed virtual machines (like JVM) in race for ultimate performance, often comes from using value types. So if we're about to go fast, we first need to understand how they work.
.NET structs represent types, which are not allocated separately on the managed memory heap, but rather inlined within the containing scope (instance of the class in case of fields, thread stack for variables, etc.). This means that usually they are cheaper and easier to access in high-allocation scenarios.
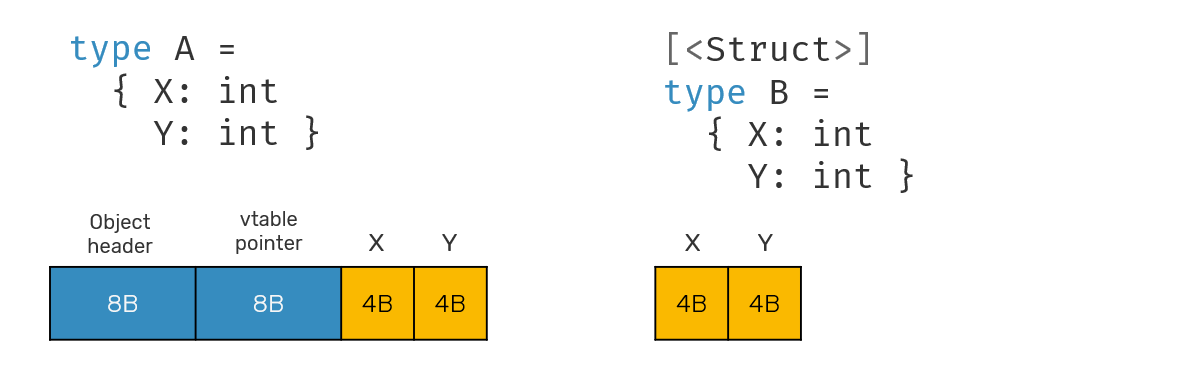
Historically, F# code was not very promising, when it comes to utilizing value types. Nowadays we got things like struct tuples - struct('a * 'b) which unfortunately are not widely used in F# even though in practice they should be preferable choice when working with tuples - and [<Struct>] attribute, that can be used on records and discriminated unions (we'll return to them later), making use of them became much more feasible.
However this doesn't necessarily mean, that replacing all reference types with value types will make our code magically go faster. In fact, this may be quite opposite. Why? Imagine what happens when we want to pass a record as a parameter. How is it done? Usually passing object to a function happens by copying reference to that object, which is either 4B or 8B depending on our OS being x86 or x64, and therefore fits perfectly into standard CPU register.
type A() =
class
[<DefaultValue>] val mutable x: int
[<DefaultValue>] val mutable y: int
[<DefaultValue>] val mutable z: int
end
let print (value: 't) = System.Console.WriteLine(value.ToString())
let a = A() // sub rsp, 0x28
// mov rcx, 0x7ff91b23d1a8
// call 0x00007ff9730aade0 ; allocate A on the heap
print a // mov rdx, rax ; copy reference to a to the stack
// mov rcx, 0x7ff91b23d5f8
// call _.print[[System.__Canon, System.Private.CoreLib]](System.__Canon)
Now what if we're using structs? For reference types we copy object's reference on the stack - since reference is just a single address, it always can fit into register and be done within a single operation. For value types, we copy entire value instead. If they don't fit into register, we'll have to copy them over in multiple steps.
type B =
struct
[<DefaultValue>] val mutable x: int
[<DefaultValue>] val mutable y: int
[<DefaultValue>] val mutable z: int
end
let b = B() // sub rsp, 0x38
// xor eax, eax ; zero field b.x
// xor ecx, ecx ; zero field b.y
// xor edx, edx ; zero field b.z
print b // lea r8, [rsp+0x28]
// mov [r8], ecx ; copy field b.x to the stack
// mov [r8+4], eax ; copy field b.y to the stack
// mov [r8+8], edx ; copy field b.z to the stack
// lea rcx, [rsp+0x28]
// call _.print[[_+B, _]](B)
Each of these steps is a machine instruction that takes time to execute. However, sometimes .NET can optimize that - pointer-sized registers are not only ones available in modern machines. We also have a special purpose SIMD (Single Instruction Multiple Data) ones, that are much bigger and can be used as long as passed data fits into them perfectly.
type C =
struct
[<DefaultValue>] val mutable x: int
[<DefaultValue>] val mutable y: int
[<DefaultValue>] val mutable z: int
[<DefaultValue>] val mutable zz: int
end
let c = C() // sub rsp, 0x48
// xor eax, eax ; zero register
// mov [rsp+0x38], rax ; init fields b.x and b.y together with zero'ed register
// mov [rsp+0x40], rax ; init fields b.z and b.zz together with zero'ed register
print c // vmovupd xmm0, [rsp+0x38] ; copy all 4 fields together on the stack using SIMD registers
// vmovupd [rsp+0x28], xmm0
// lea rcx, [rsp+0x28]
// call _.print[[_+C, _]](C)
Another thing available in .NET, that allows us addressing inefficiencies of passing structs as arguments are so called by-ref parameters. There are 3 types of these, marked using 't inref, 't outref and 't byref:
let print(value: 't inref) = ...
let c = C()
print &c // lea rcx, [rsp+0x28] ; copy address of the struct head onto the stack
// call _.print[[_+C, _]](C ByRef)
Please, don't confuse by-ref parameters with ref data type:
'a refis actually an alias forRef<'a>class, therefore allocated on the heap and passed by reference. In general, using this class in F# very rarely has sense (outside of writing exemplar, idiomatic code).'a byrefis equivalent to C#refparameter tag - it means that we're passing reference (memory address) to an object or struct. It expects it to be initialized and can be used to change the contents of the underlying value. For this reason F# requires fields and variables passed asbyrefto be declared withmutablekeyword.'a outrefis equivalent to C#outparameter tag - it always must be initialized by the end of the function body. This may sound a bit tricky as F# doesn't put that requirement explicitly. If we didn't make that assignment in any of the code branches, F# compiler will simply initialize it for us with default value (just like usingUnchecked.defaultof<_>), which sometimes may lead to null reference exceptions.'a inrefis the youngest of these and is equivalent of C#inparameter - while in C# structs passed as arguments for that parameters don't have to be tagged, F# will always require to mark passing by ref (using&prefix for passed argument) for any parameter marked withbyref/inref/outref.inrefis basically an optimization technique for what we saw above - it allows us to pass struct into a function using only its memory address, without copying entire struct contents. Additionallyinrefsays that parameter is treated as read only, so it cannot be modified inside of function body. .NET JIT can utilize this information in some cases to reduce number of safety checks, therefore reducing number of instructions to be executed.
While using by-ref parameters is usually good idea when it comes to writing code targeting complex value types, there are several limitations to it.
One is that arguments passed using by-ref params cannot be captured by closures/lambdas/anonymous functions, which prevents them from being used in more abstract code:
// WRONG!
let doSomething (a: int inref) =
[1..10]
|> List.map (fun x -> x + a) // `a` is captured by closure, which is compilation error
// RIGHT
let doSomething (a: int inref) =
let mutable result = []
for x=10 downto 1 do
result <- (x + a)::result
result
This includes problems even for common inlined functions like eg. pipe operator |>. That's the price, we have to pay for speed (at least for now).
Second issue is that, at the moment by-ref parameters cannot be involved in building nested functions (regardless if they capture the values from function in outer scope or not). This again makes very inconvenient to use them in cases like tail recursive loop pattern:
// WRONG!
let doSomething (a: 'a) =
let rec loop n (x: 'a inref) = // this nested function won't compile
if n = 0 then ()
else loop (n-1) &x
loop 100 &a
// RIGHT
let rec loop n (x: 'a inref) =
if n = 0 then ()
else loop (n-1) &x
let doSomething (a: 'a) = loop 100 &a
Readonly and ref-like structs
While we talked about by-ref params, .NET (and latest F#) enable us to do something more - we can define so called by-ref structs and readonly structs:
[<Struct; IsByRefLike; IsReadOnly>]
type BufWriter<'a> =
// since BufWriter is by-ref struct it can have by-ref types as fields
// otherwise it would result in compilation error
[<DefaultValue>] val buffer: ReadOnlySpan<'a>
/// F# records and discriminated unions are marked with IsReadOnly by default
[<Struct; IsByRefLike>]
type BufWriter<'a> = { Buffer: ReadOnlySpan<'a> }
[<IsReadOnly>] attribute let's us define given structure as being readonly. For obvious reasons this also means, that corresponding data type cannot contain any mutable fields within.
It's used as a slight optimization technique - sometimes .NET JIT compiler must guarantee that structs contents will not be modified. To do so, it will conservatively copy that structure, even when it has been passed into function using inref parameter. If struct has been marked with [<IsReadOnly>] attribute, compiler can skip this step and avoid building defensive copies. You can read more about it here.
[<IsByRefLike>] is another attribute. We are talking a lot about passing value types using memory location addresses instead of doing deep copies. Marking struct using this attribute is basically saying "I always want to pass this value by reference". This of course comes with severe limitations: it cannot be boxed (moved to managed heap) and for this reason it can never be captured by closures, implement interfaces or be used as field in classes or other non-by-ref structs.
In terms of F# this basically means that this kind of structs are used mostly for code that is executed right away within the function body, with no computation expressions or other indirections. This usually qualifies them to hot paths in our code, where CPU intensive work is expected and allocations are not welcome, like:
for .. inloops - in fact many moderns .NET structures have special variants ofGetEnumeratorthat doesn't allocate any memory and is implemented as by-ref struct. F# also understands that pattern - in fact you can define customGetEnumerator(): MyEnumeratormethod for your collection, withMyEnumerator- which can even be a ref struct - having two methods:Current: 'itemandMoveNext: unit -> bool, and F# will automatically understand how to use it in loops. You can see an example implementation of it here - it's a part of implementation of persistent vector data type, similar to FSharpX persistent vector, but it's 4.5 times faster and not allocating anything on heap when executed in loops.- Contextual data around byte-shaving operations. All things related to parsing/formatting can make use of that technique to optimize speed and reduce allocations. It's also used inside of all kinds of drivers working with I/O.
While we're using explicit class/struct type definition here, from .NET runtime point of view memory layout for records and struct records is exactly the same (it differs for discriminated unions thou, but we'll cover that soon).
Padding
Another point worth noticing is that .NET have it's own assumptions regarding data size of classes. Let's see that on an example:
type A = { x: int; y: int }
type B = { x: int; y: int; z: int }
How do you think, what's the size of A and B? Naively, we could assume that B instance would be 4 bytes bigger than instance of type A. However that's not always true. Let's inspect memory layout of both classes:
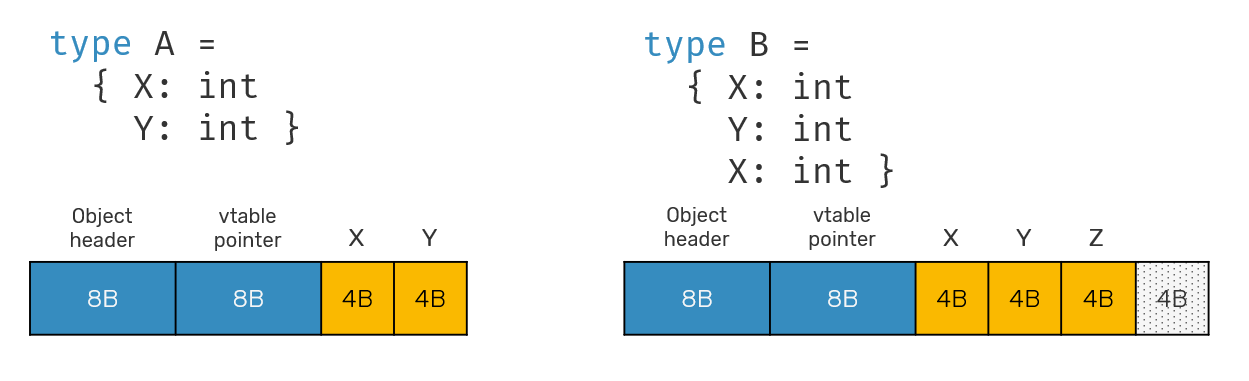
As you can see both classes start with 16 byte object header and vtable pointer: it's mandatory for every class (and boxed structs). They make things like method overriding or lock calls on objects possible. Then we have actual class content: 2 * sizeof(int) = 8 bytes in case of A and 3 * sizeof(int) = 12 bytes in case of B. However that's not the end. In case of B you can also see 4 extra bytes of padding. Where does it comes from?
When managing heap size, .NET GC/allocator makes some simplifications. Namely it assigns blocks of memory that are multiplications of a standard pointer size, which is 4 bytes on 32-bit OS'es and and 8 bytes on 64-bit ones. So, when instantiating objects, GC will always assign them as much space as it's necessary to encapsulate all fields and fit into 4-/8-bytes ceiling: since most servers operate on 64-bits nowadays, we're talking about buckets of 16+8 bytes, 16+16 bytes, 16+24 bytes etc.
What's interesting, this padding requirement doesn't concern unmanaged structs (value types consisting only of other value types). If we modify our record B to be a struct:
[<Struct>] type B = { x: int; y: int; z: int }
, we'll see that it takes only 12 bytes. If we take into account object header, that's over 2.5 less space than in case of class-based record, with no heap allocations and therefore no need to GC it later. Keep in mind that adding a reference type (eg. string) as struct field will cause it to add padding again. In that case the space saving comes from lack of object header/vtable pointer.
Now, if necessary we could also apply padding to structs manually. While in eg. Java you need to add redundant extra fields to do that, in .NET we can hint the runtime about the expected struct size:
[<Struct; StructLayout(LayoutKind.Auto, Size=16)>]
type B = { x: int; y: int; z: int }
StructLayout has many useful properties i.e. it opens the door to manually define the position of each record field within the type. It also exposes the Size property, which we can use to manually say what's the expected size of our struct - in that case when creating it, runtime will explicitly add extra bytes for padding. But what would we need it for? We answer that shortly.
CPU cache lines
We need to go a little bit deeper and step into hardware territory. Junior programmers often are taught to think about computer memory as a single homogenous block. That's a convenient lie, especially since languages - even as low level like C - rarely expose any primitives to operate on it. From computer architecture classes, you could learn that memory is split into several layers - from RAM to L1-L3 caches.

Thing is that, access time to L1 can be several dozens times faster than to main memory (RAM). For this reason, when data residing in main memory is about to be used by the CPU, it's first loaded into cache. Hardware does a little bet here: it comes into assumption that most of the data used together resides in the main memory closely to each other. For that reason it doesn't just load a single object reference - it doesn't even know what is it - but instead an entire following block of data, so called cache line. On modern hardware, cache lines are usually 64 bytes long.
One of the reasons, why we talked about structs for so long is that collections of entities like A[] behave very differently depending on A being a class or a struct:
- If
Ais a class, it means thatA[]contains only references to objects, which actual contents may reside in totally different places of memory. Given nature of .NET GC, when they are created on different threads, you may be pretty sure they will not be placed together. This means that when iterating over them, you may need to load them many times from different places in memory. - If
Ais a struct, thenA[]will contain inlined values ofA, with all their contents stored sequentially next to each other.
There's one thing about the cache lines, that can cause misleading results during microbenchmarking of the code. Consider simple operation like sum of the list values: intList |> List.sum. Let's run it twice and check the results:
| Method | Mean | Error | StdDev | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|
| TestA | 1.408 us | 0.0132 us | 0.0117 us | - | - | - | - |
| TestB | 3.964 us | 0.0189 us | 0.0158 us | - | - | - | - |
In both cases we're talking about the exactly same code over preallocated lists (so list initialization is not part of the benchmark), yet second example takes almost 3 times longer to execute. What has changed then? When setting up the test case I added extra allocation of an object in between appending nodes of the list like so:
caseA <- [1..1024] // dataset for TestA
for i = 1024 downto 1 do
caseB <- i::caseB // dataset for TestB
unused <- { x = i; y = i; z = i }::unused
Since F# list is implemented as a linked list, it means that its nodes are allocated on a heap and linked together. In first case, even thou suboptimal, those list nodes were still allocated in continuous space in memory, making more efficient use of cache line loads. In second case, our list was fragmented over much bigger space of memory. If elements of our list are value types, we can squash them together by using List. operations over it or just map it into an array. This however won't work for reference types, as we'll only move pointers alone, while objects themselves will stay in their old place.
Another way to improve performance of some operations is to revert the field order of the elements stored in collection, eg:
[<Struct>] type Point3D = { x: int; y: int; z: int}
type ContainerA(input: Point3D[]) =
member this.SumX = input |> Array.sumBy (fun a -> a.x)
member this.Item index = input.[index]
type ContainerB(input: Point3D[]) =
let x = input |> Array.map (fun a -> a.x)
let y = input |> Array.map (fun a -> a.y)
let z = input |> Array.map (fun a -> a.z)
member this.SumX = Array.sum x
member this.Item index = { x = x.[index]; y = y.[index]; z = z.[index] }
Now, depending on which operation we care about more - accessing a single element, or computing sum of X coordinates - one or another implementation will have more sense. This approach is even more prevalent if we look into world of databases - a big contributor to performance difference between OLTP databases (oriented towards standard transactional workloads) and OLAP databases (oriented towards analytical data processing) comes exactly from laying out data on a disk by rows vs by columns.
PS: In case of ContainerB we can add even better optimization techniques in form of vectorization, which we'll cover further down the blog post.
False sharing
Now the next thing is that L1-L2 caches are residing closely to CPU cores. In fact, as we've shown, every core has it's own cache. This comes with it's own problems: since every CPU has it's own copy of a value, they occasionally need to synchronize and invalidate their caches when that value is accessed from different cores. This is an expensive operation, which we want to avoid.
When such accidental sharing may happen? It's not easy to detect in micro benchmarks, and usually needs a dose of profiling and good old fashion trial and error of actual application code. IMO that's why optimizations in this area are not applied so often. Some tips to help build our intuition are:
- This can happen when two adjacent fields of the same object are concurrently accessed and modified from different threads. Thing is that unless you configure your types with
[<StructLayout(LayoutKind.Explicit)>]you won't know if two fields defined in code one after another will be placed in adjacent memory cells by .NET runtime. Using Object Layout Inspector can help you validate your assumptions here. - It can also happen that two different objects/structs will be placed closely inside of collection. This is mostly common for array-backed collections (as they keep elements continuously in memory block) and with small structs (as you may fit more of them inside of single cache line).
We can sometimes reduce risk of false sharing in 2nd case and making it more predictable, by defining type size explicitly to fit exactly into boundaries of cache lines eg. 64B (it's enough to have a class with 6 references/12 int fields or a struct with 8 references/16 int fields). If you know that your objects can be accessed concurrently, but don't fit nicely into into cache lines, you may add extra padding by using [<StructLayout(LayoutKind.Auto, Size=64)>] in your struct definition. While memory usage increases, the overall application performance may improve.
Using structs and collections together
So far, we only talked about structs in terms of singular elements - when talking about collections, we got pretty much used to the fact, that we have to allocate. This however is not always the case. .NET has a long history of allowing users to allocate collections on stack rather than heap - in C# it's related with stackalloc keyword, in F# it's bit more verbose:
open FSharp.NativeInterop
let inline stackalloc<'a when 'a: unmanaged> (length: int): Span<'a> =
let p = NativePtr.stackalloc<'a> length |> NativePtr.toVoidPtr
Span<'a>(p, length)
What we returned here is a Span<'a> - a by-ref struct type (meaning: it cannot be used in closures or as a field in most types), that allows us to address its elements just like they existed on the heap. In general, you should avoid allocating too much memory on the stack (in .NET stacks have fixed size that by default is limited to 1MB per thread, allocating over it will cause irrecoverable StackOverflowException). Most common case for using these are short parsing methods, that can be used on the hot paths without producing garbage to be collected later:
/// Parse Protocol Buffers style variable length uint32.
let readVarUInt32 (reader: Reader) : uint32 =
// var int for 32 bit values is never encoded on more than 5 bytes
let buffer = stackalloc<byte> 5
let read = reader.Read buffer
if read = 0
then failwith "trying to read var int from empty stream"
else
let buffer = buffer.Slice(0, read)
let mutable decoded = 0u
let mutable i = 0
let mutable cont = true
while cont && i < buffer.Length do
let b: byte = buffer.[i]
decoded <- decoded ||| ((uint32 (b &&& 0x7Fuy)) <<< i * 7)
i <- i + 1
if b < 0x80uy then // check if most significant bit is set
cont <- false // stop condition reached
reader.Advance i
decoded
Even though we did create a buffer (to avoid cost of multiple virtual calls to reader.Read method), in practice we didn't allocate anything that has to be later collected by the GC.
Unfortunately we cannot use spans everywhere eg. as fields of ordinary classes, but there are still situations where we might want to have collections without GC. This often desirable in case of huge number of collections, that most of the time are very small (eg. vector clocks). We can imagine such non-allocating collection like:
[<IsReadOnly>]
type HybridMap<'k, 'v> =
struct
let count: int // size: 4B
// null by default, initialized once we pass over 3 entries
// size: 8B (reference)
let inner: Map<'k,'v>
// inline first 3 entries. size: 48B = 3 * (8B+8B) (assume reference type)
let entry0: KeyValuePair<'k,'v>
let entry1: KeyValuePair<'k,'v>
let entry2: KeyValuePair<'k,'v>
end
With map like this, adding first 3 elements produce no garbage. Why only 3? Just like mentioned previously, we prefer our structs to fit into cache lines and this way (assuming both 'k and 'v types are classes) we'll still not surpass 64B (on 64bit OS) or 32B (on 32bit one).
Discriminated unions as value types
Discriminated unions are somewhat special citizens, in a sense they have to be represented in terms of .NET reference types (classes) or value types (structs). It means that depending on how they are defined (with or without [<Struct>] attribute), their in memory representation may be very different.
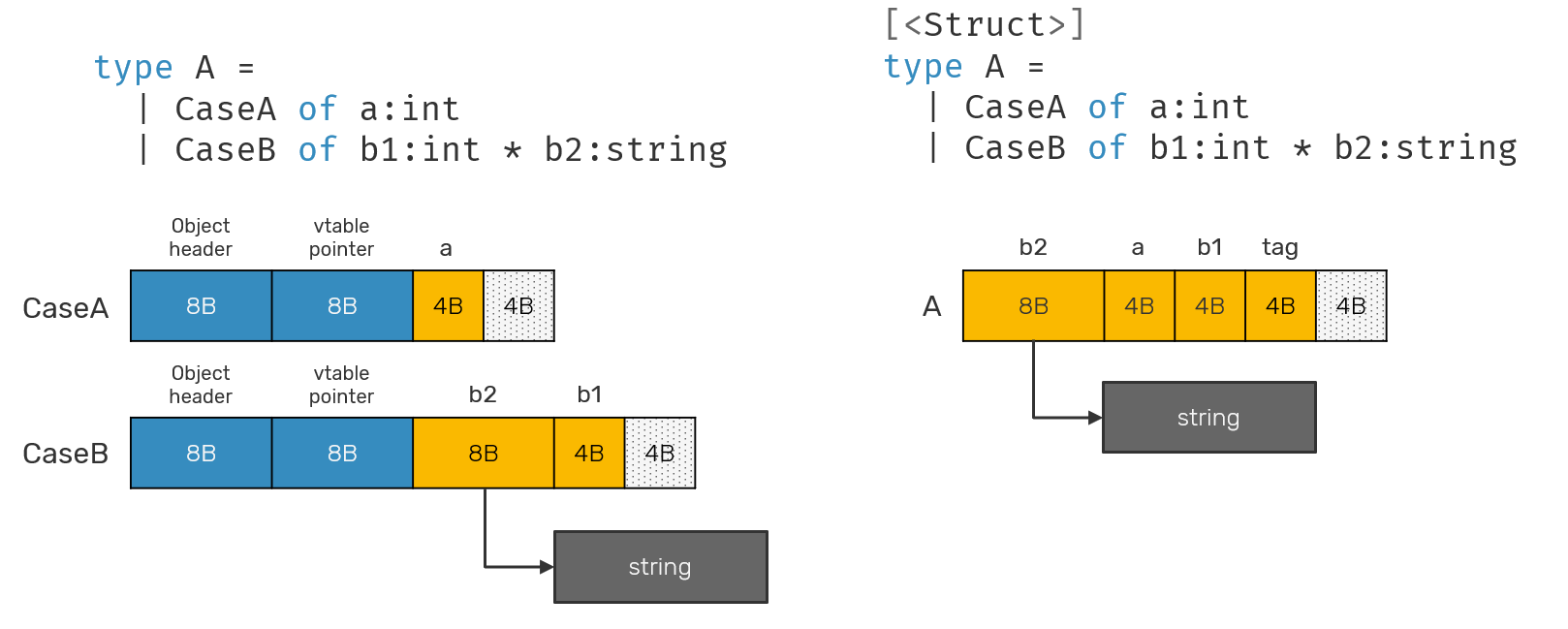
A thing you can see in both situations is that fields order in both cases doesn't reflect order in which they were defined. That's because .NET runtime can reorder them in any type unless explicitly forbidden by using [<StructLayout(LayoutKind.Explicit)>] attribute. Moreover, using this attribute is forbidden in case of discriminated unions.
Another thing, that you may have noticed is how DUs are represented. A class-based discriminated union is basically equivalent to an empty abstract class with each case being a sealed class inheriting from it. Struct based DU is more complicated. Many other languages with algebraic data types optimize the size according to formula sizeof(tag field) + max([sizeof(ADT case)]). But not F# - what we see here is sizeof(int) + sum([sizeof(ADT case)]):

The reason behind this is a limtation of .NET platform - while technically it's possible to use LayoutKind.Explicit to implement F# in similar manner to i.e. Rust, it works only as long as we don't try to use it together with generics: .NET cannot make safe guesses in that situation. In result, used memory space for struct-based DU is a sum of all fields defined all cases. For this reason good candidates for struct DU's are usually the ones with very small overall number of fields. F# standard library makes good use of these in form of Result<'t,'e> and 't voption types.
Options have somewhat special treatment when it comes to F#. While value options work pretty much in ordinary way, class-based ones have some special magic in them. We could imagine them as:
[<Struct>]
type ValueOption<'t> =
| ValueNone
| ValueSome of value:'t
type Option<'t> =
{ Value: 't }
static member Some value = { Value = value }
static member None = Unchecked.defaultof<Option<'t>> // null
This means, that value option will always have to be initialized and use sizeof(int) + sizeof('t) bytes in memory, while standard option may get optimized away into uninitialized instance (null), which size is always sizeof(IntPtr). So, while you still need to pay for allocating new object for cases where option indeed has value, in some cases where you're working with collections of mostly None values, it may turn out that using standard options is actually more effective approach.
A common scenario, where option types are used is when we're dealing with failable operations like trying to find element in a map (which may not be there) or parsing an int. In that case keep in mind:
- Using
optionis the most expensive approach, as eventual success means allocating an extra intermediate object. - Using
voptionis much cheaper, but at the moment .NET doesn't really know how to pass value types using registers alone, so returningvoptionmay mean copying it through stack in multiple steps, even though we avoided GC allocations. - In practice, the best performing solution is using straight old pattern - popular in C# - of try function definition ending up with
't outref -> boolsignature. It can be found in most .NET collections (both F# and C#), as well as parsing methods. In fact this pattern is so popular, that F# can automatically derive tuple out of it eg.let (ok, value) = map.TryGetValue(key). Under normal circumstances this tuple would mean heap allocations, however if you won't capture it and propagate further, but instead use its contents right away like i.e. inmatchexpression, it will let F# compiler to skip allocating an object.
One of the patterns sometimes used by F# programmers is to add more type info to value by wrapping it into DU:
type Mileage = Mileage of int
Patterns like this one are generally devastating for performance - we're allocating 24B of garbage on the heap for every int used. Using units of measure or even type aliases is much better option, since both of them have only compile time representation and are erased by the compiler, they never introduce a runtime overhead.
[<Measure>] type miles
type Mileage = int<miles>
Learn to work with virtual calls
Did you even wonder, when function is about to call a method on interface parameter, how does it actually know, where to find the method of the underlying object implementing that interface? Runtime resolves actual method to be called by jumping to virtual table of that object (pointer to vtable is part of object header), finding the address of corresponding method (function can have pointers too!) and calling it. As you may imagine all of that indirections can take time. If you think, you're safe because you're not doing object method calls but using module functions instead, check twice - in practice many of them are being inlined as non-static methods.
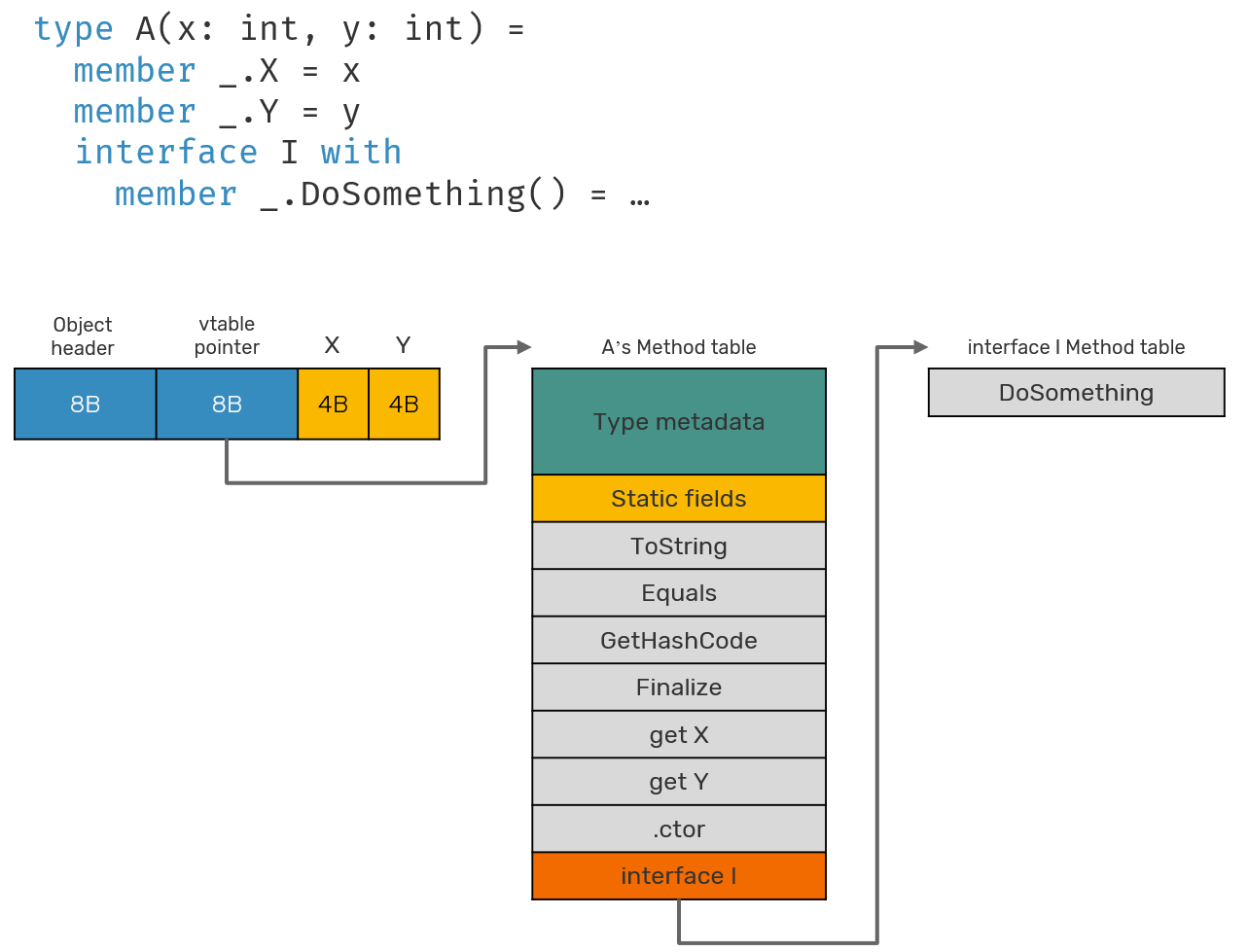
But how much longer does it actually take? Let's take an example code:
/// interface we want to test
type Stub = abstract member DoNothing: unit -> unit
/// class implementing an interface
type A() =
member _.DoNothing() = ()
interface Stub with member this.DoNothing() = this.DoNothing()
/// struct implementing an interface
[<Struct>]
type B =
member _.DoNothing() = ()
interface Stub with member this.DoNothing() = this.DoNothing()
[<MemoryDiagnoser>]
type Benchmark() =
[<DefaultValue>] val mutable a: A
[<DefaultValue>] val mutable b: B
static let execute (x: Stub) = x.DoNothing()
static let executeGeneric (x: #Stub) = x.DoNothing()
static let executeDirect (x: A) = x.DoNothing()
static let executeDirect2 (x: B) = x.DoNothing()
[<GlobalSetup>]
member this.Setup() =
this.a <- A()
this.b <- B()
[<Benchmark(Baseline=true)>] member this.ExecuteClassDirect() = executeDirect this.a
[<Benchmark>] member this.ExecuteClass() = execute this.a
[<Benchmark>] member this.ExecuteClassGeneric() = executeGeneric this.a
[<Benchmark>] member this.ExecuteStructDirect() = executeDirect2 this.b
[<Benchmark>] member this.ExecuteStruct() = execute this.b
[<Benchmark>] member this.ExecuteStructGeneric() = executeGeneric this.b
Example run from BenchmarkDotNet could give us following results:
| Method | Mean | Error | StdDev | Ratio | RatioSD | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|
| ExecuteClassDirect | 0.0356 ns | 0.0056 ns | 0.0052 ns | 1.00 | 0.00 | - | - | - | - |
| ExecuteClass | 2.2623 ns | 0.0259 ns | 0.0242 ns | 65.00 | 10.58 | - | - | - | - |
| ExecuteClassGeneric | 2.6341 ns | 0.0193 ns | 0.0150 ns | 71.95 | 8.88 | - | - | - | - |
| ExecuteStructDirect | 0.0244 ns | 0.0165 ns | 0.0154 ns | 0.68 | 0.40 | - | - | - | - |
| ExecuteStruct | 8.6782 ns | 0.1040 ns | 0.0972 ns | 249.37 | 41.07 | 0.0076 | - | - | 24 B |
| ExecuteStructGeneric | 0.6525 ns | 0.0282 ns | 0.0264 ns | 18.69 | 2.75 | - | - | - | - |
There are couple of interesting observations to be made here:
- In both cases when either struct or class type parameter is known exactly, the call itself is almost instantaneous (in fact for
ExecuteStructDirectmethod you should receive warning about entire call being optimized away). That's because runtime can say directly which version of the method is going to be called and skip the dispatch to type's virtual table. We call this devirtualization - a process, when runtime is able to replace virtual call dispatch with a direct function call. This is also the reason why you should not pass objects by interface parameters i.e.'t seqinstead of't[]any time when performance matters. - While there exists a small difference between a class instance being called via interface or as generic argument, this is not what we're after. In both cases we can observe similar results - it's because .NET 5 runtime doesn't really specialize generic method calls for reference types. At the moment it can happen sometimes for sealed classes. This means, that usually calling by interface (either explicitly or by using generic type parameter) will require virtual table dispatch anyway.
- Passing struct as parameter into a function that expects interface requires boxing - it means that this structure is copied onto heap (hence we can see allocations), prefixed with a header that includes a vtable pointer. From here struct methods look very similar to classes. All of this extra work causes the entire call to be even more expensive. Sometimes when we know that we're about to pass a struct into some callback expecting a generic object (Timer can be such example) multiple times, it may we worth to eagerly box it ahead and pass boxed version instead, reducing number of allocations. This may also be a sign that reference type is preferred over struct.
- An interesting thing happens, once we pass a struct as generic argument. As you can see, this call is several times faster than generic call on the class instance. This is because for structs, .NET JIT uses a generic code specialization - it basically emits machine code for this method call, dedicated for handling this particular type of struct when it's passed as a generic type argument. Since this is specialized branch of code, we don't need to check for vtable every time, as we already can say what function implementation is going to be called.
Generic function specialization may sound a little similar to SRTP (statically resolved type parameters - generics which are erased by F# compiler at compile time), but it's performed by .NET runtime itself. Unlike SRTP, it doesn't prolong our compile times (and .NET JIT is really fast at machine code generation) and can be composed in much better way - you can pass generic functions as parameters themselves over many levels of function calls and let .NET runtime optimize them in a wider context.
In some cases we can leverage .NET behavior to introduce something aligned to zero-cost abstractions in our code - it's a term forged by Rust programming language, meaning that we can write abstract code that's as fast as equivalent code written by hand. While .NET and F# offer it in limited scope, we can still use it. Example:
type Hasher<'t> = abstract Hash: 't -> int
let inline hash<'h, 't when 'h: struct and 'h :> Hasher<'t>> (value: 't) =
Unchecked.defaultof<'h>.Hash value
// we should introduce interface for equality check as well
type HashSet<'t, 'h when 'h: struct and 'h :> Hasher<'t>>() =
member this.Add(item: 't) =
let h = hash<'h, _> item // 'h cannot be inferred as it has no input parameter
// ... rest of the implementation
module StringHashers =
[<Struct>]
type InvariantCultureIgnoreCase =
interface Hasher<string> with
[<MethodImpl(MethodImplOptions.AggressiveInlining)>]
member this.Hash(key: string) = StringComparer.InvariantCultureIgnoreCase.GetHashCode key
open StringHashers
let map = HashSet<string, InvariantCultureIgnoreCase>()
Here we managed to introduce two improvements:
- Our collection is safer that ordinary .NET
HashSet<'t>, as we included information about what hashing method we use. TraditionalHashSet<'t>can takeIEqualityComparer<'t>as a parameter, but doesn't expose it at type level. That means, thata.Union(b)operation may yield different result thanb.Union(a)whenaandbuse different comparers and we don't get any warnings. - Our collection is also faster, because we provided a precise definition of what hashing method we use at the type level. As mentioned before, this allows .NET runtime to specialize
HashSet<'t,'h>methods over'h, since it's a struct type.Unchecked.defaultof<'h>used here is a pattern that we can use, as we cannot provide static classes (or F# modules) as generic type parameters. However we can provide a struct with no fields instead - it's in-memory representation is 0 bytes, and since it's not boxed (we're providing it as a generic value), .NET will elide its existence completely and compile it to the exact method call (no virtual dispatch is necessary here).
If you're interested more with this approach, I can recommend this presentation by Frederico Lois.
Make use of vectorization
We already mentioned registers. As you may (or may not) know, modern day processors offer general purpose registers up to 64bit size. But that's not end of the story. You might have stumbled upon term SIMD (Single Instruction Multiple Data), which was already used here - it's a technique that allows to apply the same operation to multiple values at once. It's a basis for efficient graphical processing and number crunching - hence it's a core building block for GPU programs (eg. shaders).
However pretty much every modern day CPU also have dedicated registers - varying in size from 128, 256 to 512 bits atm. of writing this post - that can also be used for this purpose. Their API has been wrapped and exposed in .NET, and it's sometimes used for common operations i.e. finding substrings in provided text or copying structs of certain sizes (we saw that already). Sometimes we call the process of making code use these specialized registers, vectorization.
You can also use them on your own. Let's a simple function that's supposed to check if value can be found within given array:
- Since vectorized operations can work only over vectors, we first need to create a vector filled in all places with value we try to find.
- Next, instead of checking array elements one by one, we load entire chunk of it (as much as we can fit into the vector), and compare it with a previously constructed comparator. This comparison is done over all pairwise vector elements in one instruction.
- Since we have to compare all vectors contents or none at all, we need to fallback to standard comparison of elements one by one, once an array remainder is smaller than vector's capacity.
#r "nuget: System.Numerics.Vectors"
open System.Numerics
let inline contains (value: 't) (array: 't[]) =
let chunkSize = Vector<'t>.Count
/// ' Use SIMD registers to compare chunks of array at once
let rec fast (cmp: Vector<'t>) (array: 't[]) (i: int) =
if i > array.Length - chunkSize then slow value array i
elif Vector.EqualsAny(cmp, Vector(array, i)) then true // compare entire chunk at once
else fast cmp array (i+chunkSize)
/// if array remainer size doesn't fit into SIMD register
/// fallback to check array items one by one
and slow (value: 't) (array: 't[]) (i: int) =
if i >= array.Length then false
elif array.[i] = value then true
else slow value array (i+1)
// create vector of 't filled with value copies on all positions
let cmp = Vector(value)
fast cmp array 0
Limitation here is that this operation works only on numbers - the smaller they are in size, the more of them can we compare at once. But is it fast? Let's check it and compare against standard F# Array.contains 900 [|1..1000|]:
| Method | Mean | Error | StdDev | Ratio | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|
| Array.contains | 1,067.2 ns | 4.58 ns | 4.28 ns | 1.00 | - | - | - | - |
| 'vectorized contains' | 271.1 ns | 1.79 ns | 1.68 ns | 0.25 | - | - | - | - |
It's 4 times performance improvement simply by using vectorized operations. There are dozens of operations defined in high-level Vector API. Knowledge on how to make an advantage of SIMD is basis for modern day design and implementation of data structures and algorithms.
Immutable code and atomic updates
Immutable data structures are prevalent technique of writing programs in functional paradigm and F# is no exception here. Thing is, that immutable structures, be it records or collections, introduce an extra overhead related to copying parts of the code in use. This can be reduced by writing structures that take advantage of structural sharing - which deserves its own blog post - but in general .NET doesn't provide optimizations that could make executing single-threaded, large scale immutable code faster than its mutable equivalent.
Often advantage of having immutable data types is not performance related - they just offer simpler way to analyze and debug program, which has fewer moving parts, as you can compare snapshots of previous/current/expected states with each other.
One of the bigger advantages - which we're also going to use soon - it's natural idempotency of such structures. Aside of being useful in testing (some of the model checkers and property-based tests make extensive use of it), we can also use it to improve performance. It's not usually visible in simple code microbenchmarking, but rather when we need to combine several different operations at once.
Example: imagine, that you have a dictionary, that needs to be updated concurrently, but also checked for size from time to time. In .NET we could simply implement it by using ConcurrentDictionary<'k,'v>, but there's a catch - have you ever wondered, how mutable concurrent dictionary ensures, that during counting process a dictionary size has not changed? Well it does it in the simplest way - it locks entire dictionary until counting completes.
open System
open System.Collections.Concurrent
let map = ConcurrentDictionary<_,_>()
// 1st set of workers tries can try to add value to a map
let write k v = map.AddOrUpdate(k, Func<_,_>(fun _ -> v), Func<_,_,_>(fun _ _ -> v))
// another worker performs operation over the elements of the map
let count () = map.Count
This issue doesn't really exists in immutable collections, since there's no risk of changing the collection as it's being iterated - we can simply iterate over old (possibly outdated) snapshot of data, but we won't stop the field/variable from being updated.
// shared mutable field
let map = ref Map.empty
let write k v = map := Map.add k v !map
let count () = Map.count !map
Now, the question would be - is it safe? Well... no. Modifying contents of F# ref cells (or even static mutable members) is not threadsafe operation. But we can make it so. How? Old school way would be to fall back to OS-level primitives like semaphores and mutexes, but we still can actually make them faster, thanks to the idempotency of immutable collections.
Atomic Compare and Swap
We'll again fallback to hardware intrinsic operations, this time exposed as part of Volatile and Interlocked classes. We can use first to make sure that our reads and writes are invalidating field values that might be accidentally reordered or cached by other CPU cores. Just like .NET runtime feels free to reorder our fields in defined types, it - of even CPU itself - can decide to reorder our operations if it deems it to be more efficient. The latter provides a set of operations, which can be executed within single processor instruction - without worrying that OS may decide to switch threads in between leaving our shared variable in undefined state.
The most powerful method in that toolbox is compare-and-swap in .NET known as Interlocked.CompareExchange, which enables to atomically swap register-sized value or reference to a new one, but only if the existing reference at the moment of swap is equal to expected one. What's important here, we're doing reference-based comparison (basically comparing pointer addresses), not structural one that we know as default in F#.
Now, here's how can we use that operation to replace locks:
let mutable map = Map.empty
let rec write k v =
let prev = Volatile.Read &map // read most up-to-date value
let next = Map.add k v prev // update operation
if obj.ReferenceEquals(prev, Interlocked.CompareExchange(&map, next, prev))
then () // we successfully updated the map
else write k v // retry
What we basically try to do is to retrieve the most recent value, update it and store back using Interlocked.CompareExchange. This operation returns a previously stored value, which should be the same reference as the one, we got prior to making an update. If it's different, it means that another thread concurrently swapped it while we were making an update. It's very rare situation, even when lock contention is fairly high, but if it happens, we just retry a whole operation.
Here, we're using Map.add but in practice this could be any function 't -> 't, as long as it satisfies few conditions:
- A reference returned by update function must be different than the input - otherwise our
ifexpression will never be able to reach the stop condition. It's one reason, why we prefer immutable data types here. - Update must be idempotent. In case of concurrent conflict, only one of the sides will win, while other will have to repeat, and we don't want to i.e. insert the same item to our list multiple times. That's another reason for using immutable collections.
- Update action should be fairly fast. No I/O operations, no number crunching. The longer it takes to execute, the less useful this pattern becomes, as risk of retries grows and their cost may outweigh the cost of acquiring the lock.
All of this puts some strong restrictions on the code that can be used with this pattern, nonetheless it's still used pretty often - especially in combination with standard locking mechanism, where we first try to optimistically use Interlocked primitives to acquire fast locks and on failure fallback to heavier ones. This is how "slim" locks work as well as thread safe queues and unbounded channels (eg. BlockingQueue).
Inlining
Inlining is a popular optimization technique, were instead of making function call, we directly emit function body in the outer function. This allows us to avoid costs like putting invocation arguments on the stack or jumps related to returning from function. In F# and .NET, there are several situations, where that happens:
- F# function itself can be marked using
inlineattribute. This will trigger F# code to literally imprint the function body at the callsite. This means that encapsulation rules of such functions must respect .NET encapsulation (eg. you cannot have public inline function calling private function in its body). Like in many other languages, F#inlineis optimistic - in some cases when function cannot be inlined eg. because it has been passed as parameter to another non-inlined function, inlining won't occur. - Any function can be forced to be inlined at runtime level by using
[<MethodImpl(MethodImplOptions.AggressiveInlining)>]attribute. It will tell JIT to emit machine code directly at callsite. This option does not have limitations of F#inlinekeyword, however it's not always able to introduce some of the optimizations, F# compiler is capable of. - Most of the time inlining happens without our precise knowledge. It can be done by the JIT compiler itself over any function not marked with
[<MethodImpl(MethodImplOptions.NoInlining)>]attribute. It's based on a set of heuristic rules, one of which being size of the calling and called functions body - the smaller they are, the higher chance for inlining to happen. Additionally at the current moment, code that explicitly throws an exception is prevented from being inlined at JIT level, so usingNoInliningoption can also improve speed of your code in some cases - most popular being exception-driven input assertions inside of functions.
As I mentioned, F# inline sometimes can apply optimizations outside of the scope of JIT optimizer alone. Let's take an example:
type AtomicRef<'t when 't: not struct>(initValue: 't) =
let mutable value = initValue
member this.Value with [<MethodImpl(MethodImplOptions.AggressiveInlining)>] get () = Volatile.Read &value
[<MethodImpl(MethodImplOptions.AggressiveInlining)>]
member this.CompareAndSwap(comparand: 't, newValue: 't): bool =
obj.ReferenceEquals(comparand, Interlocked.CompareExchange(&value, newValue, comparand))
This type is going to present behavior similar to F# ref cell, with the difference that its operations are going to be thread safe in the same sense we described in atomic compare-and-swap section. Now imagine, that we'd like to have a generic updating mechanism:
module Atomic
let update (modify: 't -> 't) (atom: AtomicRef<'t>) =
let mutable old = atom.Value
let mutable newValue = modify old
while not (atom.CompareAndSwap(old, newValue)) do
old <- atom.Value
newValue <- modify old
newValue
With this we can atomically modify a value within the cell. We could leave it like this, but if you'll benchmark an exemplar snippet like this:
// benchmark setup
val a = AtomicRef "hello"
val value = "world"
// benchmarked function body
a |> Atomic.update (fun _ -> value)
You'd discover that this call allocates - It's a result of passing a function argument (in .NET these are realized as objects), that captures value field. Now, we could try to mark Atomic.update function using [<MethodImpl>] attribute or use inline keyword. If we'd try to benchmark these however, the results would be slightly different:
| Method | Mean | Error | StdDev | Ratio | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|
| 'update (raw)' | 15.927 ns | 0.1795 ns | 0.1679 ns | 1.00 | 0.0076 | - | - | 24 B |
| 'update (jit)' | 13.089 ns | 0.1224 ns | 0.1145 ns | 0.82 | 0.0076 | - | - | 24 B |
| 'update (inline)' | 8.516 ns | 0.0743 ns | 0.0695 ns | 0.53 | - | - | - | - |
You may notice, that using attribute might slightly improve speed, but didn't change anything in terms of allocations around capturing lambda parameter. However using F# inline keyword indeed helped here: a lambda argument has been erased, as its behavior was aggressively printed together with inlined function body.
Final notes
It's been a long post, but we just touched a tip of an iceberg here. We're didn't really mention optimizations in the area of I/O operations, different flavors of async code execution or dropping .NET safety belt in cases when we wish to omit safe checks even when .NET compiler alone could not. There are also many tricky situations in which one small, seemingly insignificant change in code can throw .NET runtime into pit of deoptimized code. If you're curious about these, you can follow Bartosz Adamczewski on twitter.
Ultimately, while many of these tips and behaviors may stay with us for years to come, remember that compilers are still actively developed and just like some of these optimizations are not applied on older runtimes like .NET Full Framework, new ones (like smarter escape analysis, new devirtualization rules etc.) may turn some of the warnings presented here obsolete and shift the optimization techniques to enable us writing code that's both fast and high-level.
Comments