In this blog post we'll define the basics for a move operation used by Conflict-free Replicated Data Types (CRDT), which allows us to reorder the items in the collection. We'll define the general approach and go through example implementation build on top of YATA sequences. What's nice about our approach is that it's not limited to a single algorithm - we can easy extend it to pretty much any indexable sequence CRDT.
We won't describe the details of YATA algorithm itself, as we did so in the past. We'll go straight to implementing our code on top of it. Therefore a prerequisite for the rest of this post would be to understand that algorithm.
Use case and motivation
Imagine that you need to build music service, that enables users to create their own playlists, listen them in offline mode and is available on different devices, like smartphones or desktop. The app should be responsive, allowing users to reorder tracks on their playlist at any time, and should synchronize with user account, making changes visible on other devices they are logged in, once they get online.
The problem might arise when a person at the same time reorders their playlist on both smartphone and laptop, while these devices are disconnected. We need to ensure that - once synchronized - both devices present the same order of tracks.
While we already have discussed Conflict-free Replicated Data Types a lot on this blog, defined foundations for building indexed sequences (at least using 3 different algorithms: LSeq, RGA and YATA) and described how to insert and remove elements in them, we cannot really just remove and re-insert item at a different position for the sake of feature described above. Let's see what could happen if we try:
- We start with an initial sequence of tracks:
[A,B,C] - On our smartphone we removed
Bfrom its original position 1 and inserted it beforeA(index 0). Our expected order is:[B,A,C]. - On our laptop we removed
Bfrom position 1 and inserted it afterC(index 3 prior removal). Our expected order is:[A,C,B].
Now if we would synchronize these structures using any of the algorithms linked above, we could end up with [B,A,C,B]. This happens because each insertion counts as a new unique operation. We're not capable of establishing a correlation between previously removed element and newly inserted ones. For purpose of resolving conflicts in concurrent operations, being able to correctly describe your intent is crucial, and this is what we're missing here. We need a new method for that.
How to represent moved elements?
If we were to draw a diagram describing moving an element from one position to another, it could look like this:
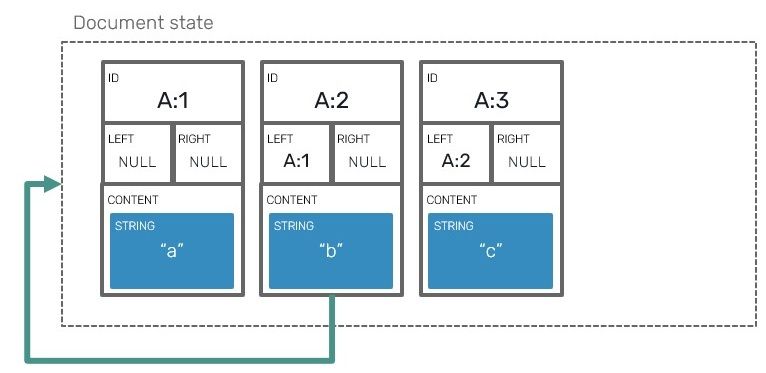
In fact this is exactly how we could represent that operation:
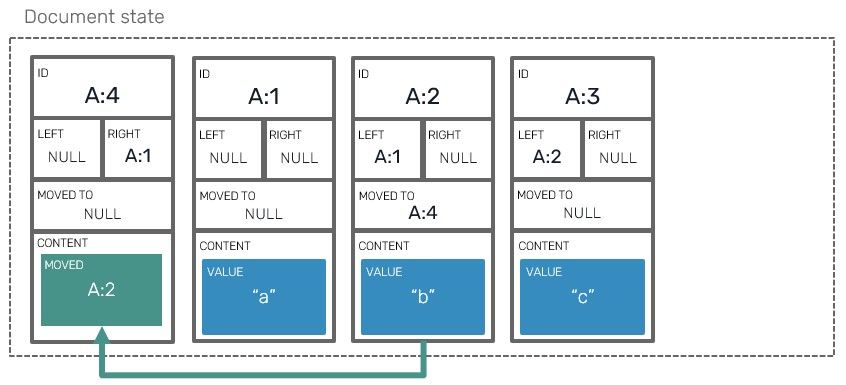
In this blog post we're going to use snippets from the following gist. It's a modified source of the solution we described last time.
As it turns out, the enhancement we need focuses around two additions:
- Add a field to a
Blockcontainer informing, that it has been moved elsewhere. - Define new type of content informing that a containing
Blockworks as a destination pointer for move operation of another block.
type Content<'t> =
| Value of value:'t // cell with a value inside
| Tombstone // deleted value
| Moved of ID * priority:int // move operation with an ID of moved block
type Block<'t> =
{ Id: ID
OriginLeft: Option<ID>
OriginRight: Option<ID>
MovedTo: Option<ID> // where current block has been moved
Value: Content<'t> }
module Block =
let isDeleted b = match b.Value with Tombstone -> true | _ -> false
let value b = match b.Value with Value v -> Some v | _ -> None
Before going further we should probably ask ourselves: do we even need that? Couldn't we just move the block physically into a new position? The answer is: NO. The core idea behind YATA (and many other CRDT sequences) conflict resolution relies on block defining its own position in relation to the neighbours at the moment when it was inserted. These origins must never change and algorithm expects to find block itself within a range bounds of its neighbours. Otherwise we'd run into either ignored or duplicated block updates during data merges, going back to square one. If we want to establish a way to resolve conflict caused by an element moved concurrently we first need to provide information that it was moved in the first place.
So how do we actually move elements? It doesn't really differ so much from inserting a new element - we need to determine neighbours at a move destination index and use them to construct our Moved block. Additionally we need to reference the block we want to move (we use its unique Id for that).
let move replicaId (src: int) (dst: int) (array: Yata<'t>) : Yata<'t> =
// get the left/right neighbours of the move destination
let dst = findPosition dst array
let seqNr = 1UL + lastSeqNr replicaId array
let left = array |> getBlock (dst-1) |> Option.map (fun b -> b.Id)
let right = array |> getBlock dst |> Option.map (fun b -> b.Id)
// get reference to moved block
let src = findPosition src array
let moved = array |> getBlock src |> Option.get
// if our moved block was already subject to move in the past,
// we need to obtain latest move priority and increment it
let priority =
moved.MovedTo
|> Option.bind (fun dst -> indexOf array dst)
|> Option.bind (fun idx -> getBlock idx array)
|> Option.map (fun block ->
match block.Value with Moved(_,prio) -> prio + 1 | _ -> 0)
|> Option.defaultValue 0
let block =
{ Id = (replicaId, seqNr)
OriginLeft = left
OriginRight = right
MovedTo = None
Value = Moved(moved.Id, priority) }
integrate block array |> integrateMoved block
For now let's forget about integrateMoved function (we'll come back to it in a second), and instead focus on priority. What do we need it for? The thing is that we might need to move the same block over the course of time more than once, while maintaining the idempotency, commutativity and associativity properties of conflict resolution algorithm. Priority field allows us to recognize that one move happened after another - this way we'll be able to correctly recognize outdated move operations.
Now let's discuss special case of move integration. The basic principle is that: whenever we put a move block into our Yata sequence, we need to check if its target block (the one that we've moved) was not already marked as moved by another operation. If so, then we have a conflict between the two moves. The way to resolve it is simple:
- The move with higher priority always wins.
- If priority of both move blocks was the same, it means that they happened concurrently. In this case our winner is the block with greater identifier.
let private integrateMoved block (array: Yata<'t>) =
// since array parameter used here is always copied,
// we can update it in-place
match block.Value with
| Moved(target, prio) ->
// we need to check if target block was not already
// moved by another operation, in such case the one with
// higher priority and ID wins
let targetIdx = indexOf array target |> Option.get
let target = array.[targetIdx]
match target.MovedTo with
| None -> array.[targetIdx] <- { target with MovedTo = Some block.Id }
| Some other ->
// this block was already moved by a different operation
let otherIdx = indexOf array other |> Option.get
let other = array.[otherIdx]
match other.Value with
| Moved(_, prio2) ->
// if we have conflict of two move operations over the same block:
// 1. the one with higher priority field (most recent one) wins.
// 2. in case of same priority (concurrent move operations),
// the one with greater ID wins.
if prio > prio2 || (prio = prio2 && block.Id > other.Id) then
array.[targetIdx] <- { target with MovedTo = Some block.Id }
| _ -> failwith "moved-to field must point to a Moved block"
| _ -> ()
array
The thing about integrateMoved is that whenever we're integrating blocks as part of merge of two blocks, this function must be called after all of the blocks have already been "integrated" into returned Yata collection. It's because Moved blocks may refer to target blocks that weren't integrated yet:
let merge (a: Yata<'t>) (b: Yata<'t>) : Yata<'t> =
// ... previous operations
while remaining > 0 do
for block in blocks do
// make sure that block was not already inserted
// but its dependencies are already present in `a`
let canInsert =
not (Set.contains block.Id seen) &&
(isPresent seen block.OriginLeft) &&
(isPresent seen block.OriginRight)
if canInsert then
a <- integrate block a
seen <- Set.add block.Id seen
remaining <- remaining - 1
// once all blocks are integrated, resolve conflicts
// between potential move operations
for block in blocks do
a <- integrateMoved block a
a
Reading blocks with respect to moves
The last step in our implementation is all about reading the values. Previously we layed blocks in array in their direct read order, which made producing results easier. Since we have moved blocks in here, we need to prepare our code to make conditional jumps and skips when iterating over blocks:
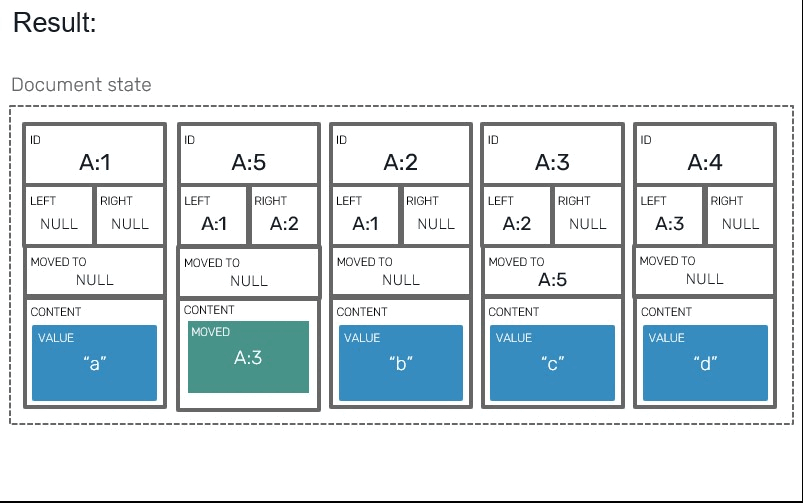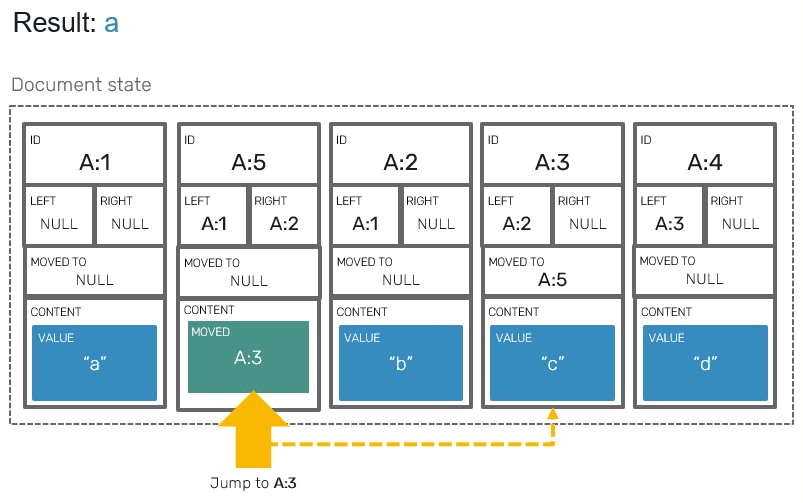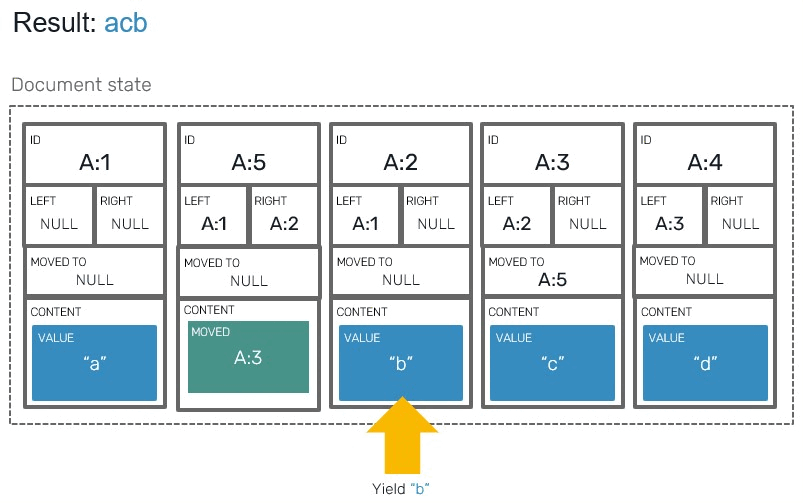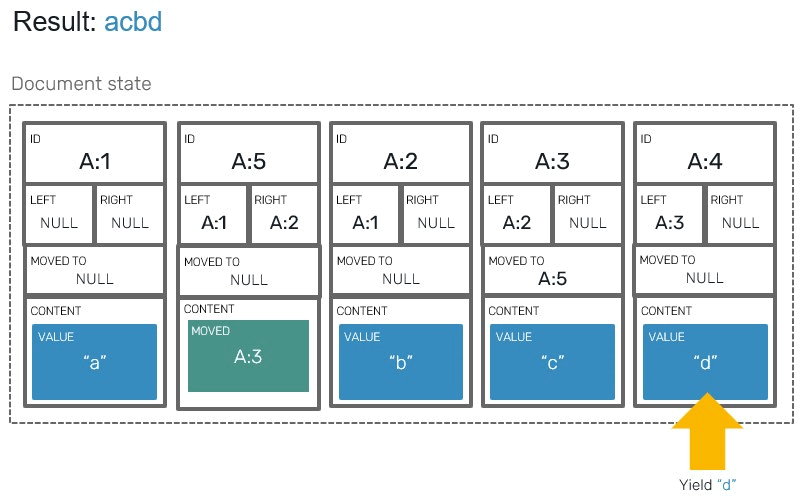
For this we'll prepare a dedicated iterator, that will respect and order of moved blocks. This is were our newly added fields will be put into use:
- If we encountered
Movedblock, we're going to make jump into its target. Since in our implementationMovedblocks will never be moved themselves, we can just do a simple single-level nested check. Otherwise our jump target could turn out to beMovedblock itself, turning jump into recursive process. - If we encountered value block, before yielding it we need to check if it's a valid target:
- Since we don't tombstone
Movedblocks, as we iterate over them several ones could trigger a jump-yield procedure, causing false duplication. It's because only one move block is valid at a time (the one which Id is present intaget.MovedTofield). - Additionally we may need to skip over the value block if it was moved elsewhere. Again we use
block.MovedTofield to determine that.
- Since we don't tombstone
// Returns iterator that produces pair of (blockIndexInYata,block).
// It skips tombstoned and move blocks.
let private blocks (array: Yata<'t>) = seq {
let mutable i = 0
while i < array.Length do
let block = array.[i]
match block.Value with
| Moved(targetId,_) ->
// jump into target block
let j = indexOf array targetId |> Option.get
let target = array.[j]
match target.Value with
// check if this block was not moved by another operation
| Value _ when target.MovedTo = Some block.Id -> yield (j, target)
| _ -> ()
| Value _ when Option.isNone block.MovedTo -> yield (i, block)
| Value _ -> () // this block was moved elsewhere
| Tombstone -> ()
i <- i + 1
}
Keep in mind that move operations now also affect the way, how to we count element offsets from client's perspective. Therefore, if we want to correctly map index provided by user onto correct block position, we need to reuse blocks iterator as well:
let private findPosition (index: int) (array: Yata<'t>) =
blocks array |> Seq.skip index |> Seq.tryHead
Moving ranges of elements
While we won't go through implementation here, let's quickly discuss, how we could extend move operations further to work not only with a single item at the time, but the entire range of elements. It could be useful in some scenarios like moving the entire paragraphs or chapters of characters in a collaboratively edited text document, while others are still editing them.
By this approach the basic structure change is that our Moved block instead of single ID target now contains a range of (start: ID, end: ID) marking the first and last block in a moved range. What's important to understand is that insertions in most CRDTs put an emphasis on a space in-between the characters, meaning that we need to decide about what happens with the blocks that are inserted concurrently at the edges of moved range - should we include them into range or not? (Example: What to do if we move paragraph, while someone is appending text at the end of it? As it happens at the edge of moved range, should it be included or excluded into move operation?)
Second change is related to reads - so far our blocks sequence function performed at most 1-step descending, when a Moved block was visited. It was easy, as by our design Moved block could never be a target of another move operation. This is no longer a case in move-range approach. As we're working towards full support to moving ranges in Yjs/Yrs, we've introduced a notion of stack:
- Each time we jump with the iterator due to visited
Movedblock, we put so-called moved frame onto a (lazily allocated) stack structure. This frame contains bounds of currently visited move range and a return position of aMovedblock itself, so that we know how to go back after we visited all moved blocks. - Each iterated block is checked against the latest move frame. Only blocks with
MovedTofield equals to that frame's return ID are yielded this way. This way we can ensure correct order of visited blocks. - Once our iterator reached end of the boundary of moved frame range, we pop that frame from the stack and revert position iterator back to the moved block that caused this frame to appear using frame's return block ID.
This approach is quite similar to how we think about call stack and function activation frames. Some of the optimizations that we use in compilers (eg. tail call optimizations) can also be applied in this algorithm.
Probably the hardest changes are related to conflict resolution of move ranges. It's because merge of concurrently moved ranges may run into hard to reconcile conflicts. Just to show the few obvious ones:
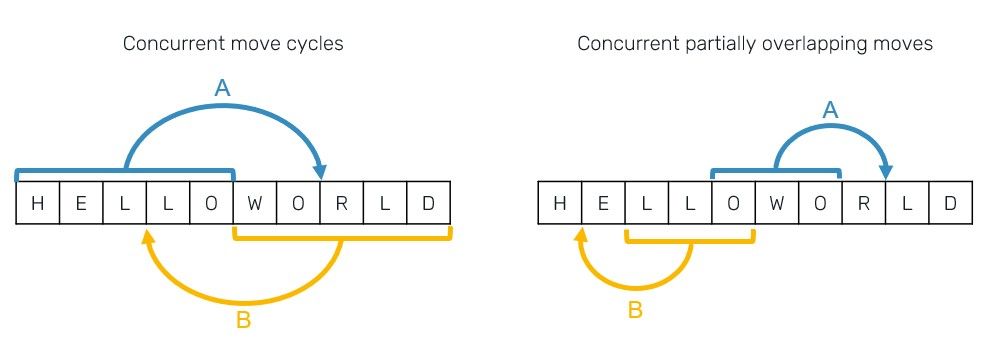
The number of cases grows as we start to add more concurrent cases and introduce different combinations of sequential-concurrent operations. Not all of these could be possibly resolved by a simple agreement between move operations - in some cases the only sensible solution would be to cancel/revert the effect of one or both move operations. Such rollback however means that we need to reapply the previous move operation that was overridden by the one we're reverting. To do so we need to remember all of the previous move operations that happened within the range of the current Moved block.
Summary
We just covered the core concepts behind the idea of moving the elements within the CRDTs sequences. While we provided an examples using a YATA algorithm as our baseline, keep in mind that these can be generalized to other structures (eg. LSeq or RGA) as well. If you're interested in further reading, your can also take a look at the slides from my presentation about YATA, which can be found here.
Comments